

BioByte 123: first steps toward a synthetic human genome, SDBench shows proficiency of language models for sequential diagnosis, Chai advances zero-shot antibody design, and the nuances of IC50s




Welcome to Decoding Bio’s BioByte: each week our writing collective highlight notable news—from the latest scientific papers to the latest funding rounds—and everything in between. All in one place.


🚨 Final week to sign up to join us for a reception to close out our third annual AI x Bio Summit on July 22! 🚨 Enjoy an evening of wine and conversation beneath the lights of the storied New York Stock Exchange trading floor as we reflect, connect, and celebrate. It’s a chance to engage with fellow founders, researchers, and operators shaping the future of biology and technology. Spaces are filling up fast so please register to reserve your spot here. We can’t wait to see you there!

What we read
Blogs
Researchers take first steps to creating synthetic human genomes [Wellcome, June 2025]
The 13-year, three billion dollar, multinational project that succeeded in sequencing the human genome was considered to be one of the greatest scientific achievements of its time. Now, once again backed by £10M of funding from Wellcome Trust, a coalition of researchers from several UK-based institutions have spun up a new 5-year project to build the tools, technologies, and methodologies necessary to synthesize a human genome. The project, dubbed SynHG, is being led by Professor Jason Chin, a Professor at University of Oxford and the Director of the Generative Biology Institute at the Ellison Institute of Technology. As a proof of concept, the team working on the project aims to construct a synthetic human chromosome with the tools they have built.
SynHG seeks to address some of the current challenges with genomic editing, chief among them being the limited size of possible edits. Synthesizing a genome from scratch would allow scientists to make changes on a far greater scale, potentially revealing causal relationships between the content & structure of DNA and the corresponding phenotype, making the potential impact for this project quite profound. Although the timeline to commercial implementation will likely take decades, SynHG will pave the way for new cell-based therapies, as well as the ability to engineer plants with new properties, a challenge of increasing import with the rapidly changing climate.
Due to the ethical implications of synthetic human genomes, the project also contains an associated social science program named Care-full Synthesis. Led by Professor Joy Zhang from the University of Kent, the program seeks to incorporate diverse perspectives into the project and ensure equitable access of its results, especially as genomic research has been historically skewed towards those with European ancestry. Although the timeline is long, the two programs will work together to ensure the research produced is used and shared in a way that maximizes its social benefit.
IC50 is a deep rabbit hole [Kris Szalay, Turbine AI, June 2025]
There is no ground truth in biology. In language, all meaning is completely derived from a sequence of characters. In biology, there is no current way of completely describing a cell with a sequence of numbers or characters.
This is a central point to the author’s dive into curating an IC50 (half maximal inhibitory concentration) data point; showcasing how easy it is to train the wrong idea because there is no perfect descriptor of a cell state. Since there isn’t a complete cell descriptor, the context in which the data was generated matters to the AI model.
A straightforward data point such as “Dabrafenib, HeLa, 50% inhibition @ 10 nM” can be misleading. IC50s have been commonly mislabeled as GI50 (growth inhibition), LD50 (lethal dose), and EC50 (half maximal effective concentration). Mislabeling the IC50 for another one of the parameters changes the measurement of the potency of the drug and the definition of the activity that is used to measure the potency itself.

The length of treatment, how the curve was fitted, how dead cell count was estimated, seeding density and physical location of the well on the plate are all additional attributes that will play into the utility of that data point. Until our field has a data type that completely captures cell state, data harmonization will remain critical.
Papers
Correction: In the originally published version of BioByte 122, release of the Tahoe-100M dataset was incorrectly attributed to Arc. The dataset was released by Tahoe Therapeutics. This has been rectified in the post.
Sequential Diagnosis with Language Models [Nori et al., arXiv, July 2025]
Rapid advances in the capabilities of language models (LMs) like ChatGPT have made such tools nearly omnipresent in our lives. However, while building coding assistants and customer service bots is one thing, integrating LMs into much more sensitive fields like medicine is a different challenge. Last week, a team at Microsoft AI released the company’s latest efforts to bring the power of LMs to healthcare and diagnostics and perhaps one step closer to the clinic. Arguing that previous benchmarks of LMs are not representative of the real-world iterative process by which a physician diagnoses a patient, the team developed the Sequential Diagnosis Benchmark (SDBench), through which off-the-shelf LMs can be validated not only for accuracy when presented with a case, but also the predicted real-world cost of the model’s proposed diagnostic plan. Furthermore, the team also released the MAI Diagnostic Orchestrator (MAI-DxO), an agent that boosts the performance by standard LMs by mimicking feedback from physician panels and aiding in test selection.
SDBench is designed to test LMs on diagnostic tasks while emulating realistic patient-physician encounters, rather than providing a model with the entire case summary. The team assembled a dataset of 304 cases from the New England Journal of Medicine (NEJM) Case Challenge series, and deconstructed them into sequences of information about a patient’s initial presentation, followed by the results of various tests and treatments. Then, a candidate LM (called a diagnostic agent) or a real physician would query a Gatekeeper agent, meant to parse each information request (corresponding to a real-world test order). The Gatekeeper agent (built on top of the o4-mini LM from OpenAI) was given complete knowledge of each case file, and was limited to providing the results of a test without any subsequent interpretation or guidance of its own. Interestingly, the Gatekeeper was also trained to generate synthetic data for a test ordered by the diagnostic agent but not actually available in the real case file. This was done to ensure models could take whatever diagnostic path they wished, rather than terminating a sequence of inquiry that a real physician might have been able to continue if they deemed fit. Finally, a Judge agent and Cost Estimator verified the accuracy of the Diagnostic agent’s prediction and totaled the monetary cost of the diagnostic sequence.

When testing an exhaustive range of off-the-shelf LMs and comparing them to real physicians, the authors found that LMs outperformed their human counterparts both in accuracy and cost of diagnostic plan. While the average physician was deemed correct approximately 20% of the time with a diagnostic cost of around $3000, the majority of LMs were able to achieve increased diagnostic accuracy (30-50%) at a similar price point. The LMs also showed an increase in diagnostic accuracy of up to nearly 80%, albeit at a proposed cost range of $4000 to $7000. To see if altered operating frameworks could boost the performance of standard LMs, the team developed the MAI-Dx Orchestrator (MAI-DxO). Under this scheme, another LM agent was used to simulate a virtual physician panel with specific roles (Hypothesis, Challenger, Stewardship, Checklist, Test Chooser). This agent could choose to ask questions, order a test, or provide a diagnosis through iterative interactions with the SDBench agents. The integration of MAI-DxO was found to boost the accuracy of off-the-shelf models while significantly reducing the cost of diagnosis.

The SDBench and MAI-DxO frameworks are fascinating demonstrations of the potential for standard, easily available LMs to diagnose patients with accuracy and cost comparable to physicians. However, the authors also admitted some limitations of their study. First, it was noted that the distribution of cases in SDBench likely deviates from the real world. Furthermore, the comparison in accuracy was only against single physicians (who were not allowed to use the Internet), who rarely diagnose a patient from start to finish and may instead rely on adjacent specialist colleagues with more niche knowledge. Finally, the AI agents currently do not account for factors like diagnostic risk to patients, the invasiveness of procedures, and variables like hospital wait times and patient comfort. Nonetheless, it’s clear that LMs and AI in general have the power to aid physicians in the inseparably human pursuit to heal.
Zero-shot antibody design in a 24-well plate [Chai Discovery, preprint, June 2025]
Chai Discovery has announced results from the second generation of their protein AI models, which builds on their previous structure-prediction model Chai-1 and integrates a new binder design module. They demonstrate the power of this model, Chai-2, in developing different classes of binders (miniprotein, VHH, scFv) towards a panel of 52 targets of various protein classes and cellular localizations.
While the team doesn’t reveal their model architecture in detail, they share a high level overview. Chai-2 is an end-to-end model composed of at least 2 submodels. Chai-2d generates one or more sequence and all-atom structure of binders to specific antigen targets, with options to specify epitope and modality (eg. scFv). Chai-2f is a structure prediction model with some advancements over Chai-1. To compare performance of antibody structure prediction, they generate structures for 152 antibody-antigen complexes outside of the training set and evaluate the binding interface using DockQ. 17% of Chai-1 structures have a DockQ score > 0.8 (which is a good score), which improves to 34% with Chai-2. For reference, Chai includes a head-to-head comparison with Alphafold2-Multimer using 5 seeds and gets <10% structures with a DockQ score > 0.8. While they aren’t able to compare directly with AlphaFold3 due to licensing issues, the AlphaFold3 paper reports ~15% when they generate structures with 5 seeds.
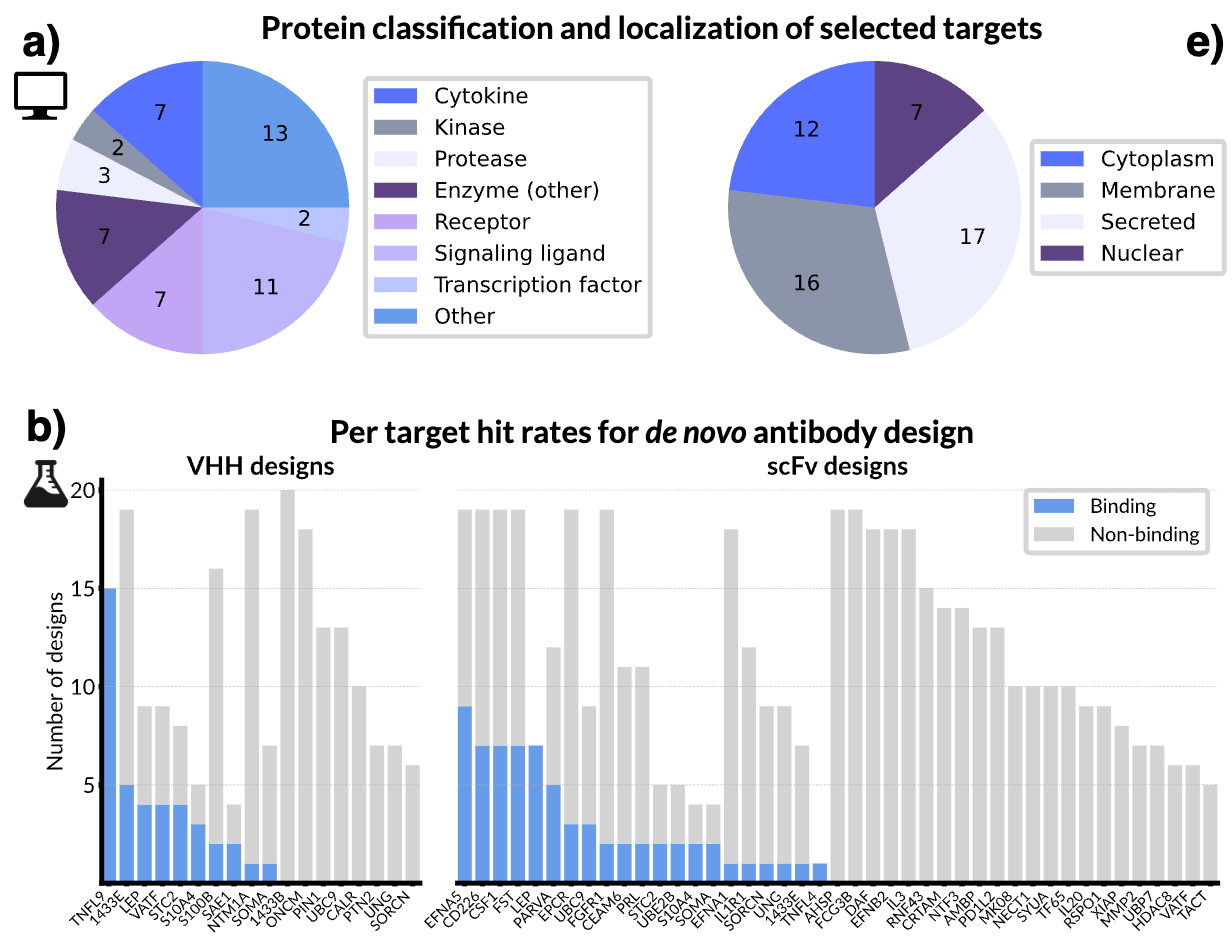
They designed 20 miniproteins, VHH, and scFv proteins to each of the 52 targets. They successfully designed binding proteins for half of the targets using VHH and scFv individually. While developing an antibody by immunizing animals (the industry standard) may take several months, this process only takes 2 weeks including wet-lab validation! The team showed they are also able to design for polyreactivity. This refers to being able to design for similar but different versions of a protein - such as the human and monkey versions of a shared protein. They designed an scFv that showed binding affinity for both the human and cynomolgus monkey of an undescribed protein.
Notable deals
Abbvie is spending up to $2.1B in cash on Capstan Therapeutics, a leading developer of in vivo CAR-T technology. Capstan develops CAR-T in vivo by delivering mRNA encoding for the CAR directly to T cells using targeted lipid nanoparticles (tLNPs) with specificity for T cells. Their first drug CPTX2309 targets CD19, one of the two receptor targets that FDA-approved CAR-T drugs have targeted - aiming to develop a scalable drug for a therapeutic modality and disease that has already been strongly validated. CPTX2309 is still in Phase 1 clinical trials, and Capstan just published work showing positive preclinical safety and efficacy data in mice and cynomolgus monkeys (covered in last week’s BioByte).
Syntis Bio has secured $33 million in Series A funding with an additional $5 million in non-dilutive grants from the NIH to support the clinical development of its once-daily oral therapy for obesity and an oral enzyme replacement treatment for homocystinuria, both of which are advancing into Phase I trials. The company was spun out of the labs of Bob Langer and Giovanni Traverso at MIT, where researchers pioneered mollusk-inspired polymer chemistry designed to enhance oral bioavailability and extend the half-life of challenging therapeutics. The funding round was led by Cerberus Ventures.
Unnatural Products has entered into a strategic collaboration with Argenx valued at up to $1.5 billion in potential milestones and biobucks. The partnership centers on Unnatural Products’ macrocycle platform, which aims to combine the target specificity of antibodies with the oral bioavailability and dosing convenience of small molecules. While financial terms of the upfront payment remain undisclosed, the alliance is expected to focus on immunological indications.
Danish biotech Cellugy has raised $9 million to accelerate the commercialization of its EcoFLEXY platform, a fermentation-based technology that produces biodegradable and high-performance cellulose materials. Designed to replace microplastics commonly found in personal care products, EcoFLEXY leverages natural biological processes to create sustainable alternatives without compromising product quality.

In case you missed it
Virtual Cell Challenge: Toward a Turing test for the virtual cell
What we listened to
What we liked on socials channels



Field Trip
Did we miss anything? Would you like to contribute to Decoding Bio by writing a guest post? Drop us a note here or chat with us on Twitter: @decodingbio.