

Scaling Bio 006: Formation Bio's CTO on Building an AI-Native Pharma
Building an AI-native drug development engine


Formation Bio is building an AI native pharmaceutical company structured to make drug development faster, cheaper, and more predictable.1 The company has raised more than $600M. It licenses promising drug assets, then runs them through an integrated development engine that uses data and modern software to remove common bottlenecks across clinical planning, trial execution, and regulatory work.
In this interview, we speak with Dan Neil, CTO of Formation Bio, about what it means to build a truly AI-native biopharma company and why clinical development, not discovery, may be where AI can have the greatest near-term impact.
In this conversation, we discuss:
Why AI’s biggest leverage today may be in clinical development rather than early discovery.
How Formation’s hub-and-spoke asset model enables learning without recreating traditional biopharma silos.
Why Formation assumes its AI platform has no standalone value outside the assets it produces.
How AI is already speeding diligence, improving clinical trial design, and reducing execution friction.
Contents
Background
Interview with Dan Neil
Background
Origins in TrialSpark
Founders Benjamine Liu and Linhao Zhang started TrialSpark in 2016 to modernize clinical operations, building tools for digital recruitment and site management used by partners such as Novartis, Pfizer and Sanofi. Realizing that more efficient clinical execution changes the economics of drug development, the team began acquiring assets and rebranded as Formation Bio in 2023 to combine platform and asset ownership.2
Becoming Formation Bio
More efficient trial execution fundamentally changes the economics of drug development. If a company can run more trials per dollar and per unit time, it gains a structural advantage not just as a service provider, but as a drug developer. With the confidence that its platform could materially outperform traditional development models, TrialSpark decided to develop assets themselves, transitioning into an integrated pharma company and later rebranding as Formation Bio in 2023.3

Formation operates as a hub-and-spoke model, where new assets are in-licensed or acquired and structured under subsidiary companies.4 This helps manage portfolio risk while allowing Formation to apply their more efficient drug development processes to each drug in their pipeline. The company raised a $372M Series D in 2024.
Formation Bio’s AI Platform
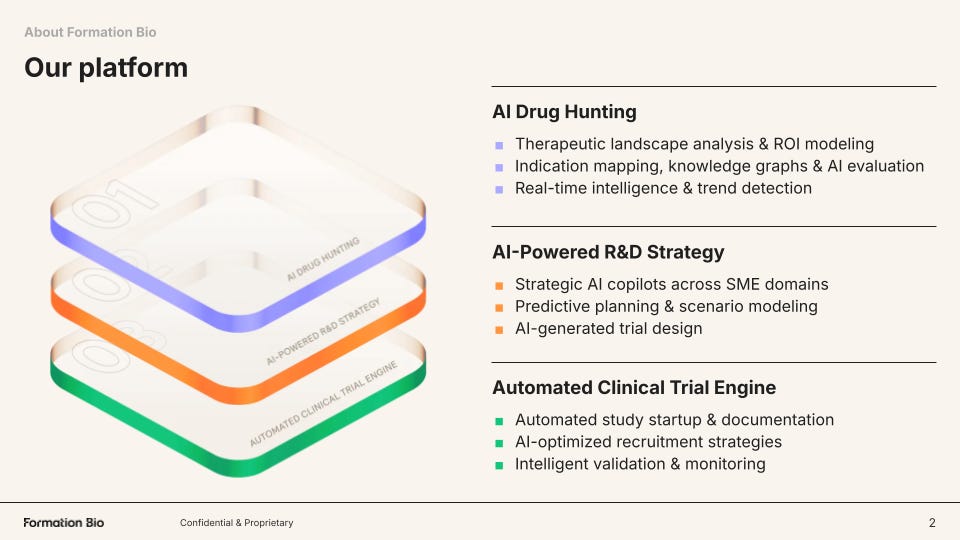
Formation structures its technology around three core pillars and a shared knowledge backbone called ARK:
AI Drug Hunting
First, the company builds tools to source the best drugs for in-licensing or acquisition. Two key axes drive this effort: finding available assets faster, and building the strongest possible intelligence around whether those assets are likely to succeed clinically.
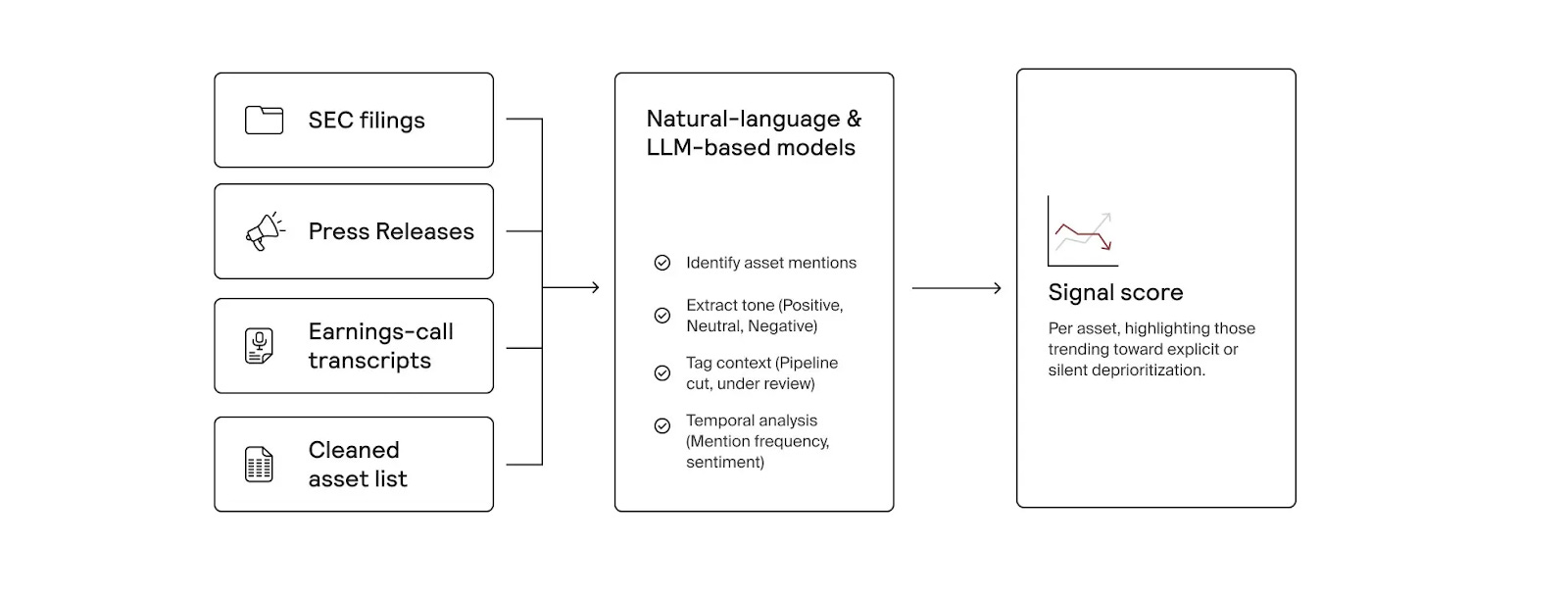
Formation has built an AI-native system that continuously scans public and proprietary data to identify high-potential drug assets for acquisition or licensing. Beyond tracking publicly available opportunities, it searches for “dark assets,” programs that may be quietly deprioritized or shelved before public disclosure.5 By analyzing sources like news reports, SEC filings, and earnings call transcripts, the platform detects early discontinuation signals, giving Formation’s business development team potential first-mover advantage in pursuing deals.
On the other axis, Formation’s genetics pipeline integrates human genetic evidence directly into asset selection and diligence, improving decision quality when evaluating new drug candidates.6 For each asset, the platform assesses genetic support for efficacy, potential safety risks, and signals for additional indications. Results are synthesized into structured reports in minutes, allowing Formation to scale rigorous genetic diligence across large deal pipelines.
AI-Powered R&D Strategy
Formation also builds tools to improve R&D strategy, which is critical because development decisions around trial design, indication selection, and resource allocation ultimately determine whether a drug succeeds or fails. Specifically, the company has built a harmonized clinical trial data stack that converts historically fragmented trial, literature, and real-world datasets into structured, machine-readable knowledge that can be queried and modeled at scale.7
Automated Clinical Trial Engine
From its roots as TrialSpark, Formation Bio has built software and now AI tooling that accelerates clinical development. One of those tools is Muse, its AI patient recruitment system built with Sanofi and OpenAI to accelerate one of the largest bottlenecks in drug development. Muse compresses patient recruitment strategy and material generation from months to ~15 minutes.8
Muse automates patient recruitment by synthesizing scientific, clinical, and population data to identify target patients and generate tailored outreach at scale. Because recruitment is a major driver of trial cost and timelines (and fewer than ~10% of eligible patients enroll), accelerating and improving patient matching directly speeds development and time-to-data.
Tying it all together: ARK (AI-ready Repository of Knowledge)
Formation is building a competitive advantage around data and knowledge integration that allows it to both find the highest-quality drug assets and develop them more effectively over time. As the company built systems across Drug Hunting, genetics, clinical data intelligence, and automated trial execution, it became clear that the long-term advantage would depend on whether insights could flow seamlessly across these domains rather than remaining siloed in individual tools or teams. Formation built ARK to solve this problem internally, creating a unified backbone that allows data, models, and learnings from across the organization to compound.9
ARK is implemented as an MCP gateway that standardizes access across Formation’s internal data, external scientific and clinical datasets, operational systems, and AI model endpoints through a unified interface and permission layer. Over time, this turns every asset evaluation and clinical program into a structured data-generation event, enabling continuous model improvement and compounding their institutional intelligence. Employees and agents alike can query ARK to access the depth of intelligence Formation produces.
Quickly Growing a Robust Pipeline
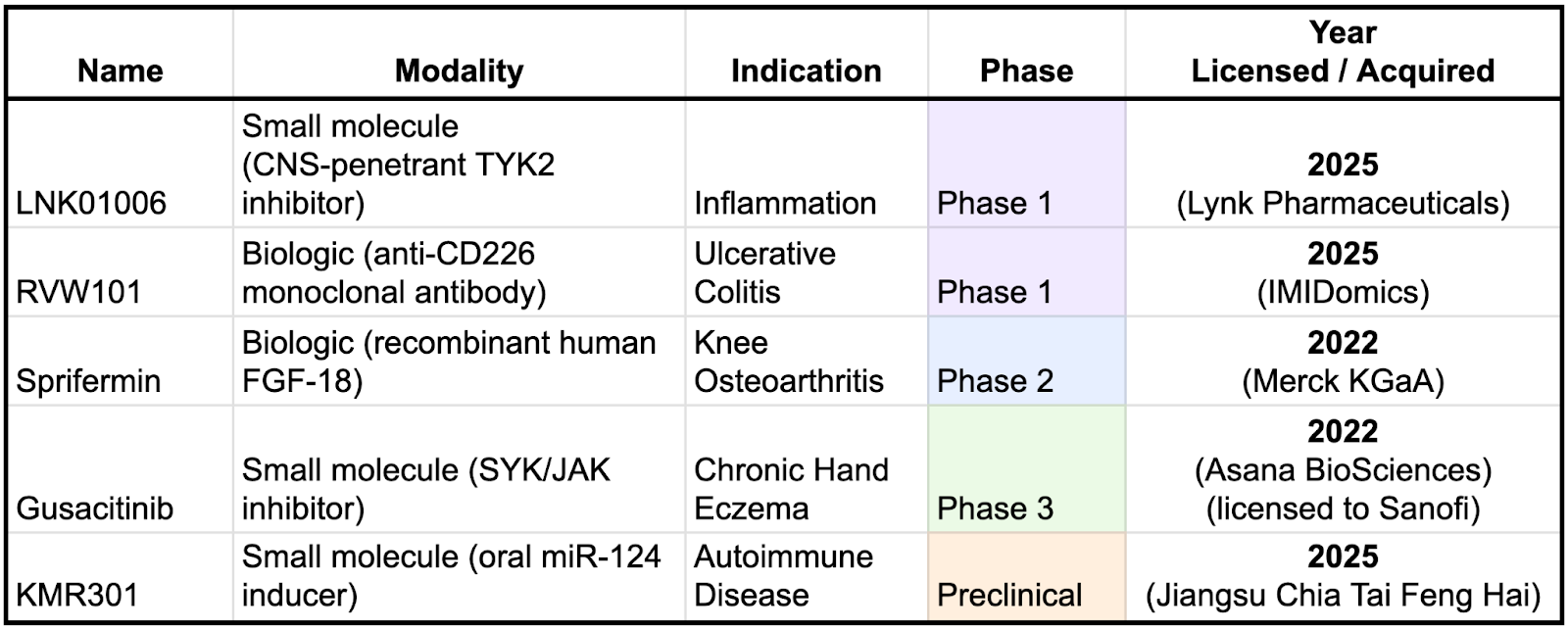
Formation is rapidly building out their pipeline, having licensed three of these drugs in 2025 alone. One notable pattern is that Formation’s more recent licensing activity appears to be shifting toward earlier-stage assets. This likely reflects increasing confidence in its platform and operating model, as well as a growing ability to assess risk and value earlier in the development lifecycle. Strategically, this shift is important: earlier-stage in-licensing typically comes with lower upfront costs and the potential for greater ownership and downstream economics if programs succeed.
Dan Neil, CTO
Formation is among the forefront of companies exploring how AI can be used to accelerate clinical development - building new tools and organizational philosophies of how a pharma company should be structured. To learn more about Formation’s vision of the AI-native pharma company of the future, we spoke with their CTO, Dan Neil. Dan earned his PhD and MSc in machine learning and neuroscience at ETH Zurich after studying biomedical computation at Stanford. He served as CTO at AI biopharma BenevolentAI, helping it scale all the way through a public listing. Most recently, Dan was CTO of Tessera Therapeutics, leading their AI/ML strategy in development of gene editing-based therapies. As CTO of Formation Bio, Dan leads efforts to grow the company’s AI platform to accelerate their drug hunting and drug development efforts.

A Conversation With Dan Neil
Contents
Value Creation and Platform Economics
Practical Applications in Asset Acquisition and Clinical Trials
From Discovery to Development
You’ve had a diverse career path, starting with a PhD in computational neuroscience at ETH Zurich, then computational roles at Tessera Therapeutics and Benevolent AI, and now Formation Bio. What drew you to make the move from these early drug discovery companies to clinical development?
Early drug discovery is exciting, but it faces a significant bottleneck: clinical development, where very few programs succeed. Despite enormous R&D effort, only about 50 drugs are approved in the US annually. I recognized the need to focus on this critical bottleneck - drug development - which is Formation Bio’s core strength. Formation Bio tackles the clinical trial process using technologies such as AI, enabling more of the early drug discovery therapies to actually translate to the clinic.
One could argue that truly breakthrough early discovery would eliminate many downstream clinical bottlenecks. From your experience at early-stage AI discovery companies, where does AI genuinely add value today, and where does it still fall short?
AI in early discovery tends to work well in narrow, well-defined tasks — such as protein design, target ranking, or hypothesis generation — but drug discovery rarely fails for a single reason. Clinical assets often break down due to a combination of factors: off-target effects, safety liabilities, poor tissue exposure, or unexpected biology.
Current AI systems typically optimize one dimension at a time. To materially change clinical outcomes, they would need to reason across all of these constraints simultaneously, which remains an open challenge. As a result, improvements at the discovery stage do not always translate into higher probabilities of clinical success, which is why clinical development continues to be the dominant bottleneck.
Formation has evolved from site optimization to CRO work to now in-licensing assets. How intentional was that progression?
Very intentional. Ben and Linhao, our founders, will tell you we had to earn the right to each next stage. Discovery companies face extremely long feedback loops: it can take many years to know if your process works. We started at the opposite end. If we make site startup 10% faster, that saves actual dollars today. We demonstrated we could run trials efficiently, then showed we could manage other people’s assets. Through that, we earned the right to take on our own. Now with our fund structure, we can in-license drugs every year and run structurally more efficient clinical trials. The goal is to create this generation’s biopharma company: truly AI-native.
The Technology Stack
You’ve worked across computational neuroscience, AI-driven discovery, and now clinical development. What ideas or technologies have persisted across those experiences and shaped the platform you’re building at Formation Bio?
Across all of those contexts, the core lesson has been the same: no single model solves biology. Different machine learning approaches are powerful in different settings, and the real challenge is architecting systems where each model contributes what it is best at.
I started my PhD working with knowledge graphs, and later used protein language models and large language models at Tessera and BenevolentAI. All of these techniques remain useful, but only when they are applied in the right context. Knowledge graphs, for example, are still valuable for reasoning about biological plausibility and causal mechanisms, while LLMs are excellent at synthesizing large volumes of unstructured scientific evidence.
At Formation, that philosophy shows up in how we structure the platform. We invest in three core technology areas. First, tools that help us search for and evaluate drug assets, what we think of as the AI drug hunter. Second, tools that help design better clinical programs. Third, tools that help execute trials faster and more efficiently.
The most interesting architecture is in asset evaluation. When we assess a potential acquisition, we are dealing with enormous data rooms full of documents, experiments, and readouts. LLMs are very good at synthesizing that material, but they can also be confidently wrong. To mitigate that, we layer in additional systems, such as knowledge graphs to sanity check biological plausibility and specialized models for areas like ADME and toxicology.
The key is the integration layer. Each component produces structured signals, and the system brings them together into a coherent, auditable decision process. No single model is responsible for the final answer, and nothing operates end to end in isolation.
It sounds like there still needs to be a human with strong scientific judgment in the loop. Are you trying to train models to eventually develop that kind of scientific taste?
The long-term goal is for models to develop something close to human scientific taste, but today we are very much in a learning phase. To get there, we first need to systematically observe how the best human drug hunters actually make decisions.
At Formation, that learning signal already exists. David Steinberg, our Chief Business Officer, has built a very strong team of drug hunters and business development experts. Every asset they evaluate goes through a structured six-tier funnel, scored across roughly ten criteria, including scientific plausibility, safety, and transactability.
What makes this powerful is that the process captures more than a single score. For each criterion, the team records their confidence in the assessment and how damaging it would be if that judgment were wrong. Across dozens of assets each month, this creates a growing body of structured decision data that reflects real expert judgment under uncertainty.
Today, that data helps save time and surface red flags. Over time, it becomes the foundation for teaching models how experts reason about tradeoffs, risk, and confidence, which is what scientific taste really is.
Are you post-training or fine-tuning models on that proprietary decision data?
Not directly, at least not yet. I don’t want to compete with major research labs on training foundation models. They already do an excellent job at high-dimensional, in-context reasoning.
Instead, we decompose the problem. Rather than building a single end-to-end model, we break the workflow into components and use specialized AI or machine learning systems where they make the most sense.
In some cases, that’s a traditional ML model, like a blood–brain barrier predictor based on molecular structure. In others, it’s an agent designed to read and reason over specific data, such as rat toxicology reports. Each component produces structured signals that feed into a larger decision system.
The integration across all of that evidence is deliberately left to large foundation models operating with full scientific context. Our focus is on making sure the right signals exist and are well structured, not on replacing the foundation layer itself.
How do you measure whether these AI tools are actually being helpful?
We focus on real-world outcomes rather than abstract benchmarks, and the metrics differ by technology area.
For asset acquisition, we look at things like evaluation speed, conversion rates, and agreement with expert reviewers. For clinical program design, we measure predictive accuracy for enrollment rates, timelines, and costs, and reconcile those predictions against what actually happens. For trial execution, we track concrete operational metrics, such as site startup time, screening rates, and patients enrolled per site per month.
One of the advantages of working in clinical development is that impact is tangible. If the tools are working, timelines get shorter, execution improves, and costs go down. Those are the signals we care about.
Prioritization and Strategy
As CTO managing multiple product teams across so many different workflows, how do you even begin to prioritize where to focus?
I think about prioritization through three lenses.
First is time to impact. Some ideas are very promising but take years before they influence real decisions. Large cell atlases linking perturbations to disease phenotypes are a good example. In contrast, a specialized system that helps analyze rat toxicology or safety data can be useful immediately. That near-term impact is often undervalued, and AI has opened up a lot of low-hanging fruit that can matter right now.
Second is alignment with the company’s current stage. Right now, Formation is in full purchase mode, so asset acquisition is where most of my focus goes. As more clinical trials come online over the next year or two, attention will naturally shift toward execution tooling.
Third is reserving space for long-term research bets. I try to keep roughly 10–15% of effort focused on ideas that may not pay off soon but could fundamentally change how the industry operates. AlphaFold is the canonical example of that kind of dark-horse breakthrough.
Can you give an example of one of those longer-term bets?
One question I think about a lot is what actually drives clinical trial success, and how early you can predict it. There’s a clear through line from the tools we already use in asset diligence to this problem.
If you could quantitatively assess whether an asset shows true causal biology and estimate the likelihood of Phase 2 success at the point of licensing, that would be enormously valuable. The earlier you can make that call with confidence, the less you pay for the asset and the more value you can ultimately realize. That remains an open problem, but it’s the kind of direction that could meaningfully change drug development decisions.
Value Creation and Platform Economics
Where does Formation Bio’s biggest value creation come from? Could the AI platform have standalone value?
I bear the scars of trying to make that true. I would love platforms to have standalone value, but the industry doesn’t really reward that. Platform value tends to be judged entirely through the lens of asset outcomes, even though background success rates in biotech are extremely low. You could double the probability of success and still fail most of the time.
I’ve seen companies where high platform valuation and high asset valuation looked great, but when an asset failed, the platform was blamed and the company collapsed.
The less satisfying but more realistic answer is to assume the platform has no independent value. Its value only manifests through the assets you create.
That’s the model we follow. When we worked with Sanofi, we gave some of our technology away. If it’s useful, people will use it. That approach lets us avoid sales, maintenance, and customer feature requests, and stay focused on getting drugs to patients faster and better.
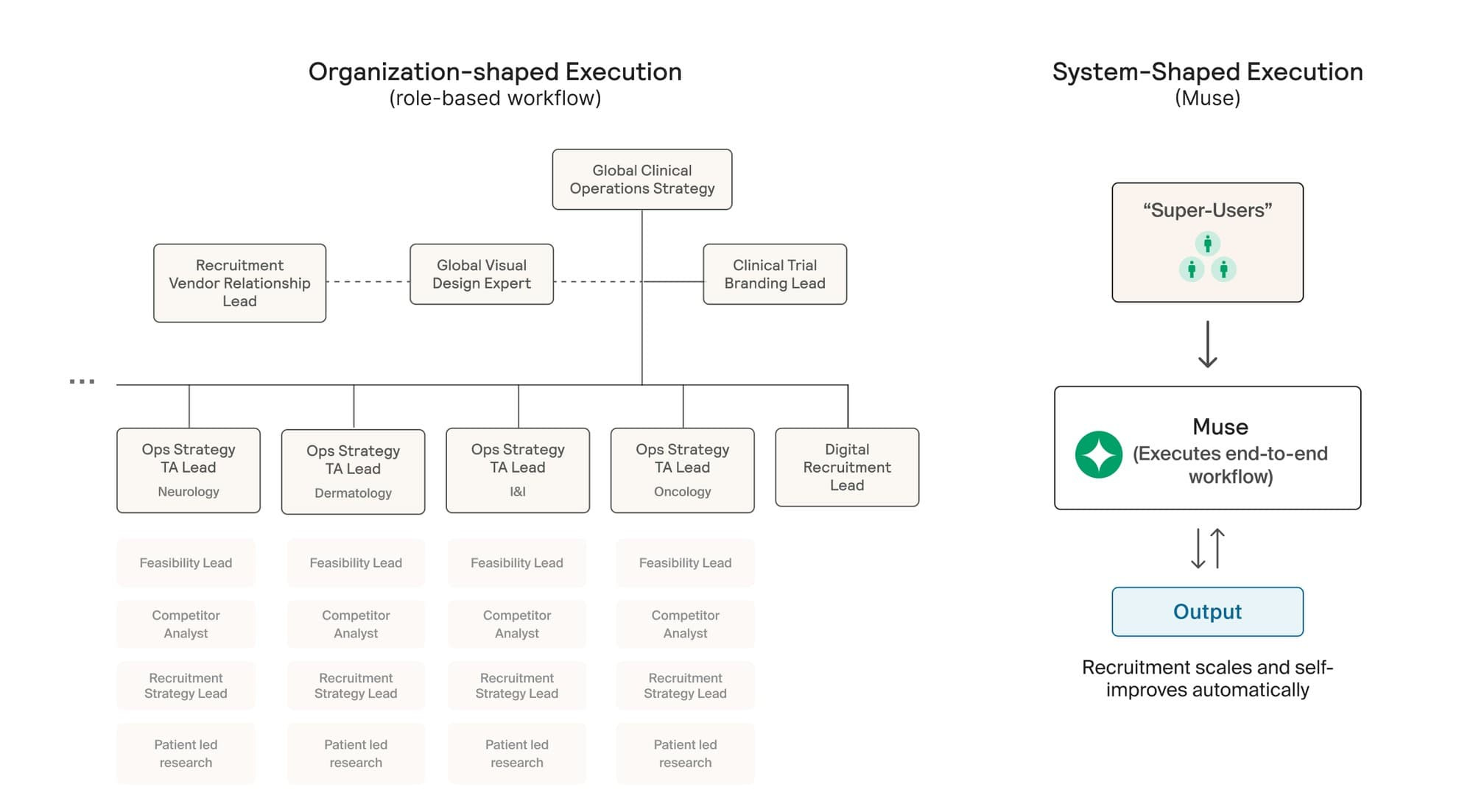
Formation operates a hub-and-spoke model, with assets housed in separate subsidiaries. Does that risk recreating traditional pharma silos?
It would, if the spokes were truly independent and learning stayed local. That would just recreate the same silos, only at smaller scale.
We’re very deliberate about avoiding that. Each spoke is focused on executing a specific asset and indication, but the underlying data architecture is shared. What teams learn about biology, trial design, patient recruitment, or failure modes flows back to the hub and becomes reusable.
That shared layer is what allows the platform to compound. A Phase 2 failure in one spoke isn’t just a loss, it’s a data point that improves how we evaluate risk, design trials, and assess future assets across the portfolio.
What’s the biggest bottleneck preventing biopharma from achieving that kind of data fluency?
Change management. Large organizations are built around disease-area teams with specialized skill sets, and creating meaningful cross-linkages is hard.
This is where technology can help, but only if it’s paired with organizational change. At some point, you should be able to query your internal knowledge and get answers. That’s much easier to build into a company that’s still forming than to retrofit into one with tens of thousands of employees.
How does Formation hire and structure teams to support that collaboration?
Hiring is the hardest and most important part. We explicitly screen for collaboration. Our interview process includes cross-functional interviews to ensure people can partner across the business and bring humility to their expertise.
The second piece is communication infrastructure. We’re moving internal knowledge into queryable systems so teams can see what’s been done before, what data exists, and what insights have already been generated. Technology supports that, but it only works if the culture expects information to flow.
Would you ever license or sell this internal data architecture to other companies?
I’d almost want to avoid that. Integration is one of the hardest parts, and this technology is still evolving quickly. People are still figuring out how to combine AI note-taking, query systems, structured databases, and agent frameworks in a way that actually works.
More importantly, the process of building and adopting these systems is part of the change management. When AI tools are rolled out top-down, adoption is weak. When tools are made available and teams discover how they’re useful, adoption is much stronger. The architecture that works for us may not be the right one for another company.
Practical Applications in Asset Acquisition and Clinical Trials
You recently in-licensed the microRNA-124 asset. How did AI tools give you alpha on that decision?
Two things. First, we have a robust internal toolset for clinical planning. A system called Forge lets us iterate on trial design very quickly. We try to shift left everything that could matter. If, before acquiring an asset, you already know the clinical trial you would run, the expected recruitment rate, the cost, and the timeline, you can price the asset much more accurately.
We use these tools early in diligence. Traditionally, you would only develop a detailed clinical plan after acquisition, often over several months. Having that insight upfront lets us move faster and transact with more confidence.
Second is risk adjudication. We use AI systems to red-team assets, surfacing questions or failure modes that human reviewers may not immediately catch. We are still evaluating how accurate these systems are, but they already help broaden perspective during diligence.
On clinical trial execution, where are the most concrete friction points where AI can help?
Site monitoring is a good example. The fact that risk-based monitoring exists at all suggests there is room for improvement. Today, monitoring frequency is adjusted manually based on perceived site risk. With better data harmonization and real-time pipelines, you could move toward more continuous monitoring.
Another practical example is regulatory communication. We recently drafted materials for the FDA using the newest generation of language models to help organize hundreds of pages of information, generate initial drafts, and run first-pass analyses. It’s not glamorous, but it cuts time roughly in half, which compounds meaningfully in clinical development.
How much data do you need to build a clinical trial predictive engine?
There is already a large amount of relevant data available. ClinicalTrials.gov is a core resource, but we also integrate electronic health records, claims data, scientific literature, and knowledge graph sources to build a more complete picture.
What’s changed recently is that much of this information used to exist only as unstructured text. Large language models now make it tractable to turn that into structured signals. As we run our own assets from preclinical stages into the clinic, we also create closed-loop datasets that connect early evidence to clinical outcomes, which further improves the system.
Does the technology affect your relationship with the FDA?
Everyone is using these tools now. Humans are still fully accountable for what gets submitted, but AI is increasingly part of how documents are drafted and analyzed. The FDA is exploring similar tools internally as well. I view this more as a partnership than a tension point, with the shared goal of working more efficiently while keeping humans responsible for decisions.
With the FDA becoming more open to Bayesian trial designs and your focus on data harmonization, could data eventually flow more continuously rather than through large phase-based submissions?
I’m open to anything that accelerates learning while maintaining rigor. That requires rethinking how trials are architected, how data flows, and how conclusions are drawn. There are opportunities to explore designs that generate signal earlier and more continuously. Ultimately, the FDA wants safe, effective medicines to reach patients faster, and that aligns with where the industry is heading.
Therapeutic Areas
Much of your pipeline is in immune-related diseases. Is that a deliberate focus?
Less than it might appear. We have a broad mandate and look for alpha wherever we can find it. Some recent assets have been immune-related, but that’s not our only focus. We do have an explicit non-oncology bias because oncology has its own unique complexity. As buyers, we are also influenced by what high-quality assets are available in the market, and right now there are compelling opportunities in immunology.
How does the ability to predict clinical success vary across disease areas?
It varies meaningfully. There is well-established evidence that assets supported by human genetic data have two to three times higher success rates. When we build prediction systems, we incorporate as many relevant features as possible and use mechanistic interpretability methods to understand which signals matter most. Feature importance looks different across therapeutic areas.
Benchmarking is challenging in biology because historical datasets can be incomplete or outdated. We try to anchor our models by benchmarking against live clinical trials that are about to read out, keeping evaluation as close to real ground truth as possible.
Lessons and Future Vision
Has there been a product or research decision you made with high confidence that didn’t work out?
Many of these problems are extremely high-dimensional, which makes it easy to build models that perform well on a single axis but fail overall. One example for me was graph-based reasoning over knowledge graphs. I tried encoding drugs as graph motifs linking mechanism of action to disease and using that to adjudicate future assets. In practice, the models gravitated toward trivial or misleading patterns, such as nearby diseases or ideas that had already failed.
What worked better was using richer representations and presenting extracted reasoning paths to human experts, who are much better at contextual interpretation.
Any advice for people building in the AI biotech space?
It’s an incredibly rich time to be in the space. Whether it’s protein language models, workflow optimization, imaging, or data infrastructure, there are many ways to apply technology to improve patient outcomes. I wouldn’t be surprised if multiple areas produce breakout successes in parallel.
Any final thoughts before we close?
For the first time in 250 years, we get to reinvent what a company is. We’ve had this pyramid structure since the East India Company, ossified during the Industrial Revolution. The last major transformation was Alfred Sloan and departments at General Motors in the 1920s. For 100 years, nothing has changed.
Now we have AI. The way we organize ourselves into companies is something we can innovate on for the first time in a really long time. Information architecture is a big part of that, and is one of the things we’re working on right now.
For my longer thoughts on how AI will change the shape of an organization, especially a pharma company, read our blog post.
Thank you Dan!
Go formation and go Danny!!
For a longest time I've only seen negative posts about AI - and I agree, it begins to look dangerous and I'm still not convinced some people should be allowed to use it, but it's really nice to see that some individuals have the creativity and motivation to use it for good. I believe that medicine - including pharmacology - could really benefit from smart use of AI, and this post is a perfect example. Good luck with that project! 💖