As large language models (LLMs) become increasingly prominent and intelligent, reshaping the way we work day-to-day, important questions emerge about their potential to accelerate and enable groundbreaking scientific discoveries. At the forefront of this effort is FutureHouse, an organization dedicated to exploring these possibilities. This piece examines their unique approach and current progress in this exciting domain.
The PaperQA and WikiCrow team at FutureHouse.
FutureHouse is pioneering the development of an AI scientist: a system designed to automate the process of scientific hypothesis generation and testing, with the goal of accelerating the pace of innovation in biology and other complex sciences.
FutureHouse is similar to a Focused Research Organisation (FRO), in that it is a non-profit initiative dedicated to open science. FutureHouse (and FROs) pursue ambitious, academically oriented scientific challenges with the agility, resources, and team structure of a start-up, typically without relying on conventional academic grants for funding.
Launched in November 2023 and based in San Francisco, FutureHouse is primarily funded by Eric Schmidt and operates with a team of ~22. The organization is structured into two key areas:
Science Team: Applies AI agents to conduct open-ended exploration, generate hypotheses, and validate them in their own wet labs.
Platform Team: Develops and scales the AI agents, integrating feedback from the scientific process.
FutureHouse envisions automated scientific discovery as a four-layer framework, where each layer builds upon the last to create a comprehensive system with human oversight embedded. The layers consist of:
Tools: Tools include models and interfaces that one can use to make predictions about the world or manipulate the world. This includes lab equipment, computational tools (e.g. BLAST), and machine learning models, like AlphaFold3, Evo and other foundation models.
AI Assistants: This layer consists of models capable of executing specific tasks, such as literature reviews or searching clinical trial databases.
AI Scientists: The centerpiece consists of autonomous agents capable of managing the entire scientific workflow and each layer. Unlike AI assistants that perform isolated tasks, AI Scientists oversee the entire process, from designing experiments to hypothesis testing. The agent can change course after each step, depending on what information it has gathered so far. This is a key feature of an agent approach as opposed to a standard linear process such as retrieval augmented generation (RAG).
Humans: The ‘end-game’ is for a human to define a “Quest” (or scientific task) and for the AI Scientist to autonomously execute the research flow, producing novel hypotheses that can be tested in the lab.
Schematic of the four-Layer AI Scientist framework.
Schematic of the AI Scientist’s workflow.
To date, FutureHouse has released many tools including PaperQA: a system that retrieves and summarizes information from scientific publications. It is one of the first AI agents to achieve super-human performance in diverse scientific literature search tasks. FutureHouse expects to release more agents for other steps in the process of scientific discovery.
Today, we are joined by Sam Rodriques, the CEO and co-founder of FutureHouse. Sam’s academic background includes training in physics and neuroscience in Ed Boyden’s lab at MIT. Before launching FutureHouse, he briefly led a bioengineering lab at The Francis Crick Institute in London, where he developed innovative technologies across spatial transcriptomics, brain mapping, and gene therapy.
Zahra: What inspired the idea for FutureHouse?
Sam: During my neuroscience PhD in Ed Boyden’s lab, I wanted to understand how the brain works. One key realization was that even if we had produced all the knowledge needed to understand the brain, no single individual could sift through the decades of fragmented literature or reconcile the myriad of non-standardized experiments. I felt that our ability to make big discoveries is limited by our ability to synthesise information and plan the right experiments. And so, I began to wonder if the most impactful thing I could do is to create computational systems that could manage this complexity better than humans. This idea stayed with me throughout my time at the Crick.
Zahra: Can you share an example where sifting through decades of existing literature has led to a meaningful outcome?
Sam: A straightforward example comes from drug discovery. There’s a serendipitous case where researchers identified a novel use for an existing compound by uncovering overlooked data in the literature. While this is only one example, the broader idea is clear: systematically mining the vast troves of scientific literature can reveal hidden insights and connections, potentially accelerating discovery and innovation.
An example of a drug discovery outcome with a heavy literature search component.
Zahra: How did you go from that initial idea to raising funding from Eric Schmidt and launching FutureHouse?
Sam: The rapid emergence of LLM capabilities was a big turning point. I was also developing the concept of an FRO with Adam Marblestone, which led me to meet Andrew White and Eric Schmidt. Over the course of a year, I brainstormed with Eric and refined the concept into a formal proposal. Relationship building is crucial - it’s hard to pitch an ambitious idea and gain traction without a track record, so the year I spent really working with Eric was crucial for the final raise.
Zahra: Will FutureHouse ever be for profit? What does FutureHouse look like in its steady state?
Sam: It’s too early to say. Our primary goal is scientific discovery and maximizing impact. We’ll adopt a model that ensures we can make discoveries available to as many people as possible. This research needs to be open and not withheld by private organizations. To achieve this, we need significant resources, including software engineers to build infrastructure, which isn’t feasible within a traditional lab setting.
Zahra: How do you choose what projects to work on?
Sam: The guiding metric for choosing projects is whether they lead to new scientific discoveries. This is how we will measure our success. There is no formal process. We are a small organisation and an advantage is the ability to start and stop new projects.
Our structure includes:
A science team focused on exploring potential paths and generating hypotheses.
A platform team responsible for developing the tools and scaling the systems.
We explore possible directions and then prioritize the most promising paths for further development.
FutureHouse Organization Structure.
Zahra: Do you think the current state of LLMs is sufficient to create a truly enabling AI scientist? Is the challenge now more about data engineering and infrastructure?
Sam: Today’s models operate at what I’d call “B-level intelligence.” They’re far from matching the capabilities of a graduate student, especially in biology, where the complexity is immense. However, they excel in scale. For example, PaperQA can analyze in minutes what might take a human months to do. Imagine applying that speed to pooled screening across 100,000 experiments. Even if only a small percentage yield meaningful results, the scale itself can drive breakthroughs.
That said, for AI to truly revolutionize scientific discovery, models need to advance to “A-level intelligence.” This requires more than algorithmic improvements - it demands robust tools, better infrastructure, and seamless integration with existing scientific workflows. For instance, models need easy access to supplemental materials and experimental data, which current systems struggle to provide. Even o-1 does not yet reach human performance on these tasks. We are also not aiming for “human” performance, but even more superior performance.
I believe these challenges are within our grasp and that within the next two years, AI systems will generate the most novel scientific hypotheses, surpassing humans.
Zahra: Could you walk us through Lab-Bench, your recent preprint on large language models’ scientific reasoning capabilities?
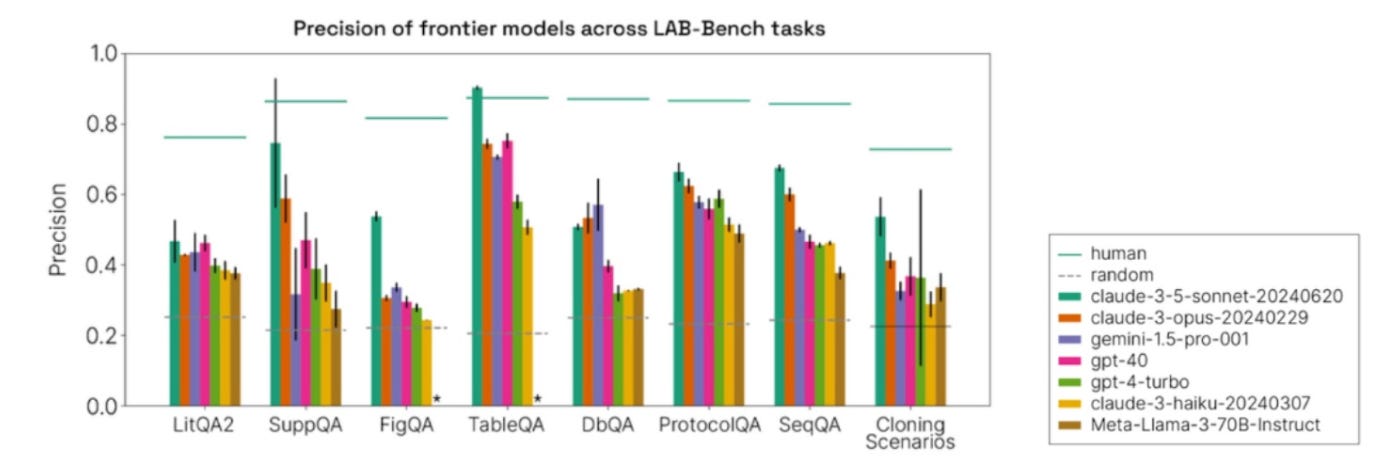
Sam: Lab-Bench introduces a benchmark of 2,000 questions designed to evaluate scientific reasoning and task performance, all manually validated by humans. For example, FigQA is a component focused on critical reasoning over scientific figures.
We tested various frontier models available at the time on this benchmark. For the questions the models attempted, their performance was compared against humans and random guessing. Interestingly, models like o-1, which weren’t available on initial testing, now perform at human-level for tasks like ProtocolQA.
Performance of frontier models on the Lab Bench evaluation set. Results indicate performance on questions the models chose to answer. Note o-1 was not included.
Lab Bench evaluation set of scientific reasoning tasks.
Zahra: One of the limitations of current language models is the lack of access to tools that human researchers can use. Is FutureHouse looking at this?
Sam: Absolutely! Many of the above scientific tasks require the use of tools, and thus, tool access. Current models lack this capability, and part of our focus is on bridging that gap to unlock their full potential. We recently released Aviary, an environment that gives language models access to the same scientific tools as humans. The language model and the environment interact to enact a workflow described as the language decision process (LDP). This enabled open-source language models with modest compute budgets to surpass human performance on two of the lab-bench tasks (scientific literature and reasoning about DNA constructs).
An overview of the five implemented Aviary environments and the language decision process (LDP).
Zahra: What makes the agentic approach more powerful than RAG workflows for scientific discovery?
Sam: A good example is PaperQA, which functions as an agent. To contrast, consider a linear workflow like RAG. In RAG, the process is predefined: it searches for papers, extracts information, and generates an answer step-by-step. In contrast, an agent takes on the role of a controller. It dynamically decides its next steps—searching for papers, gathering evidence, and adapting its approach. For instance, it might identify an interesting author and follow that lead or refine its search terms based on what it finds. Such agentic systems will also be able to command the use of tools e.g. alphafold, to test their hypothesis real time before the final suggestions are given to the human.
Our thesis is that this agentic approach is inherently more powerful for scientific discovery. An agent doesn’t just execute a fixed workflow; it reads papers, summarizes them, identifies relevant chunks, and uses those to refine its search iteratively. This flexibility and adaptability make agents uniquely suited for complex, exploratory tasks.
Zahra: So, what will the role of human scientists be in this future?
Sam: In the future, AI will generate hypotheses and design experiments based on data analysis, while human scientists will shift to a more strategic oversight role - evaluating proposals, allocating resources, and guiding research direction. This leverages AI's ability to process vast amounts of information with humans' judgment and expertise to accelerate scientific discovery.
Zahra: What is one of the biggest challenges for FutureHouse?
Sam: One major challenge is the experimental bottleneck: we still lack a virtual cell or virtual human. This forces reliance on real biology and model organisms, which limits the speed at which hypotheses can be tested. It also doesn’t address the high costs of in vitro and in vivo experiments or their limited representativeness of human outcomes. However, AI scientist agents aim to tackle this by optimising experimental efficiency - identifying the best cell line or model for the given scenario and creating an experimental plan that minimises the risk of error in every experiment.











Seems like a cult - probably going to turn up like Theranos, they have nothing new or innovative so far.
Good informative about science and AI in the future