

Scaling Bio 009: Benchling's Ashu Singhal and Nicholas Larus-Stone on Building the AI Scientist Inside the Notebook
How a decade-old electronic lab notebook is remaking itself for the AI era: the harness, the wet-lab automation, and the open question of how long the data moat lasts.

The term "AI Scientist" has become commonplace across the research community, with companies on every side claiming to build one: dedicated startups like Edison Scientific, frontier labs like Anthropic and Google DeepMind, academic groups like James Zou's lab at Stanford, and the specialist biology model builders themselves, from Recursion to Isomorphic Labs. So what does a notebook provider that has spent more than a decade as biotech's system of record have to claim in that space?
Over the last eight months the company has shipped a lot toward the bet: Model Hub for running scientific models, Benchling Inference, Benchling Automation, AI connectors, and an AI Scientist. The wager threaded through all of it is that a decade spent owning biotech’s system of record, both the structured and unstructured data plus the workflows on top, is exactly what lets Benchling build a vertical agent that horizontal tools cannot match for real scientific work.
The obvious counter is whether that is durable. If frontier models keep getting better at reading messy, unstructured data, and if cross-customer learning is off the table for IP reasons, is a per-customer system of record a strong enough moat to defend the AI layer on top of it? Is it even necessary anymore? If Benchling depends on third-party providers for the models, why wouldn't customers just go to those providers directly? And if a specialized agent really does beat a general one, as Benchling argues, doesn't that same logic cut against Benchling, the generalist spanning the whole lab, next to the model builders developing core expertise on the drug discovery workflow?
I sat down with co-founder and president Ashu Singhal and Head of AI agents Nicholas Larus-Stone to talk through all of this and more.
In this conversation, we explore:
Why Benchling believes the advantage in scientific AI comes from owning the data layer and the workflows, not the models themselves.
How its harness stays deliberately model-neutral, ensembling across LLMs, search providers, and scientific models, and why “more is better.”
Why a vertical, purpose-built agent beats horizontal agents like ChatGPT, Claude, and Cursor for novel research.
How Benchling is closing the lab-in-the-loop, and why the hardest problems sit in the messy middle between full automation and fully manual work.
Whether a per-customer system of record holds up as a moat when models can increasingly read messy data and cross-customer training is not on the table.
Where humans stay indispensable, and why adoption, not model capability, is the binding constraint.
Overview
Benchling was founded in 2012 by Sajith Wickramasekara and Ashu Singhal, who met at MIT, with the goal of bringing modern software to life sciences R&D. Over the following decade it became the system of record for the field: an electronic lab notebook layered with molecule registration, inventory, and analytics, now used by more than 1,300 biotech companies ranging from emerging startups to Merck, Moderna, and Sanofi. Along the way, Benchling has accumulated both the structured scientific data and workflows that scientists generate, as well as the unstructured context around them. This turns out to matter enormously for grounding agents and models.
Over the past year Benchling has built an AI suite on top of that record, and developed a tight ecosystem of partners alongside:
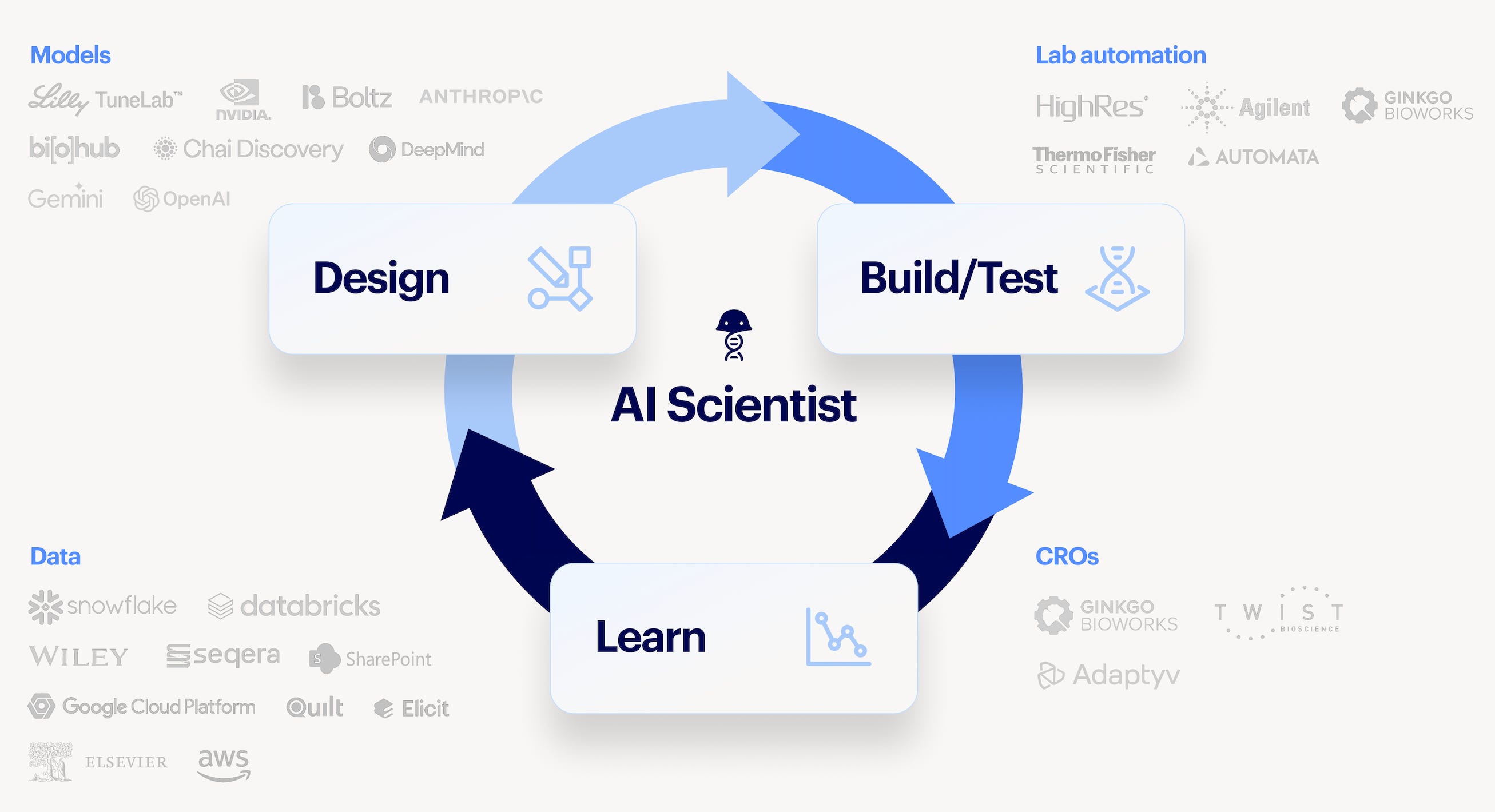
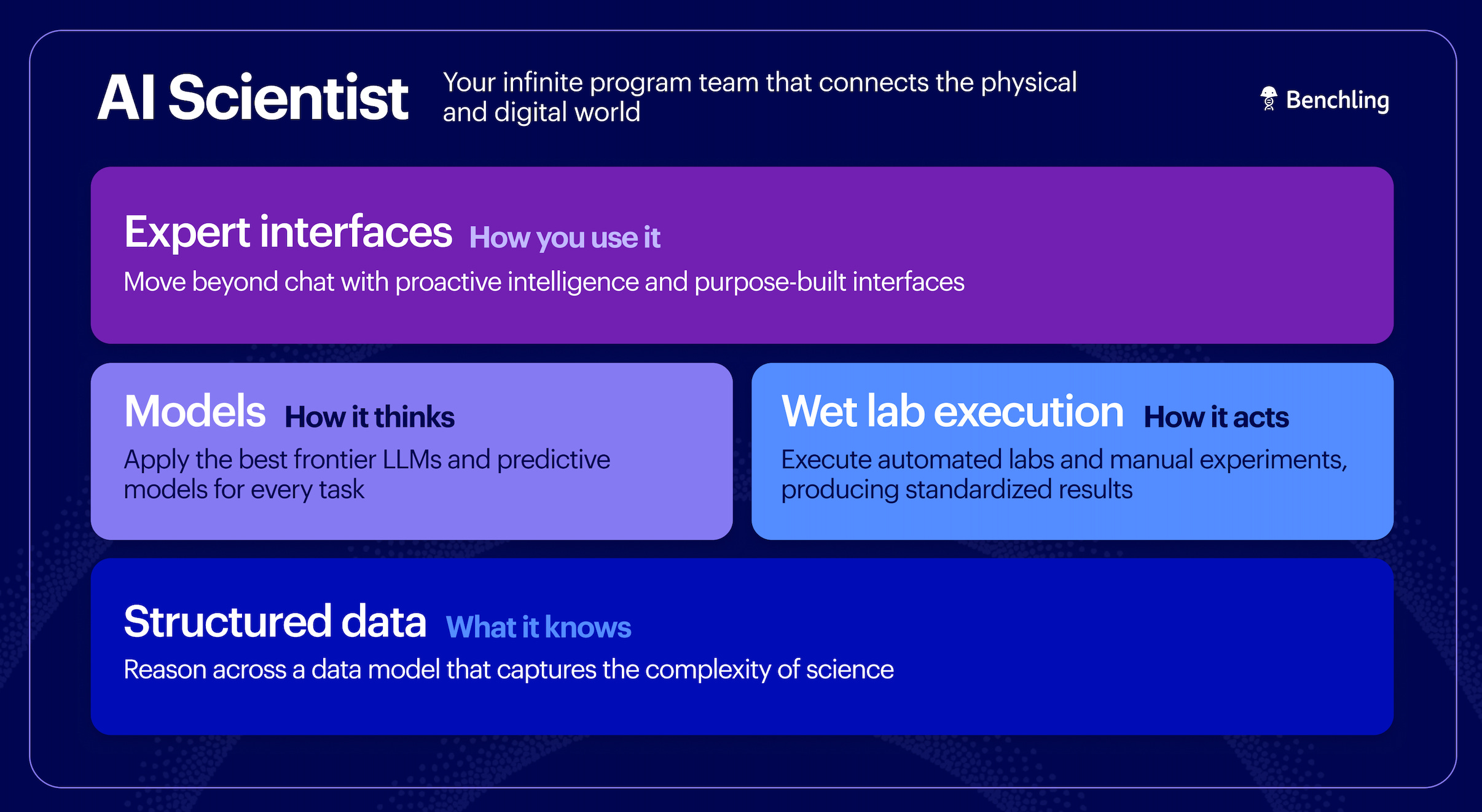
Benchling AI. A single agent that works directly inside the notebook entry: it analyzes experimental data, retrieves related historical experiments, writes and runs code, generates plots, drafts entries, and assembles multi-experiment reports. It is grounded in Skills, reusable packages that encode scientific and organizational knowhow (out-of-the-box Skills cover report writing, statistical analysis, and data import), and Connectors, MCP-based links that pull in external context from systems like SharePoint, Snowflake, UniProt, and the public literature. The end-to-end version of this that connects experiments across the digital and physical lab is what Benchling calls the AI Scientist.
Model Hub. A space to discover, run, and track external scientific AI models (such as Boltz’ model suite) alongside experimental data, with full traceability to source records.
Benchling Inference. Built with Baseten, this gives customers on-demand GPU capacity spanning 15+ cloud providers with fast cold starts.
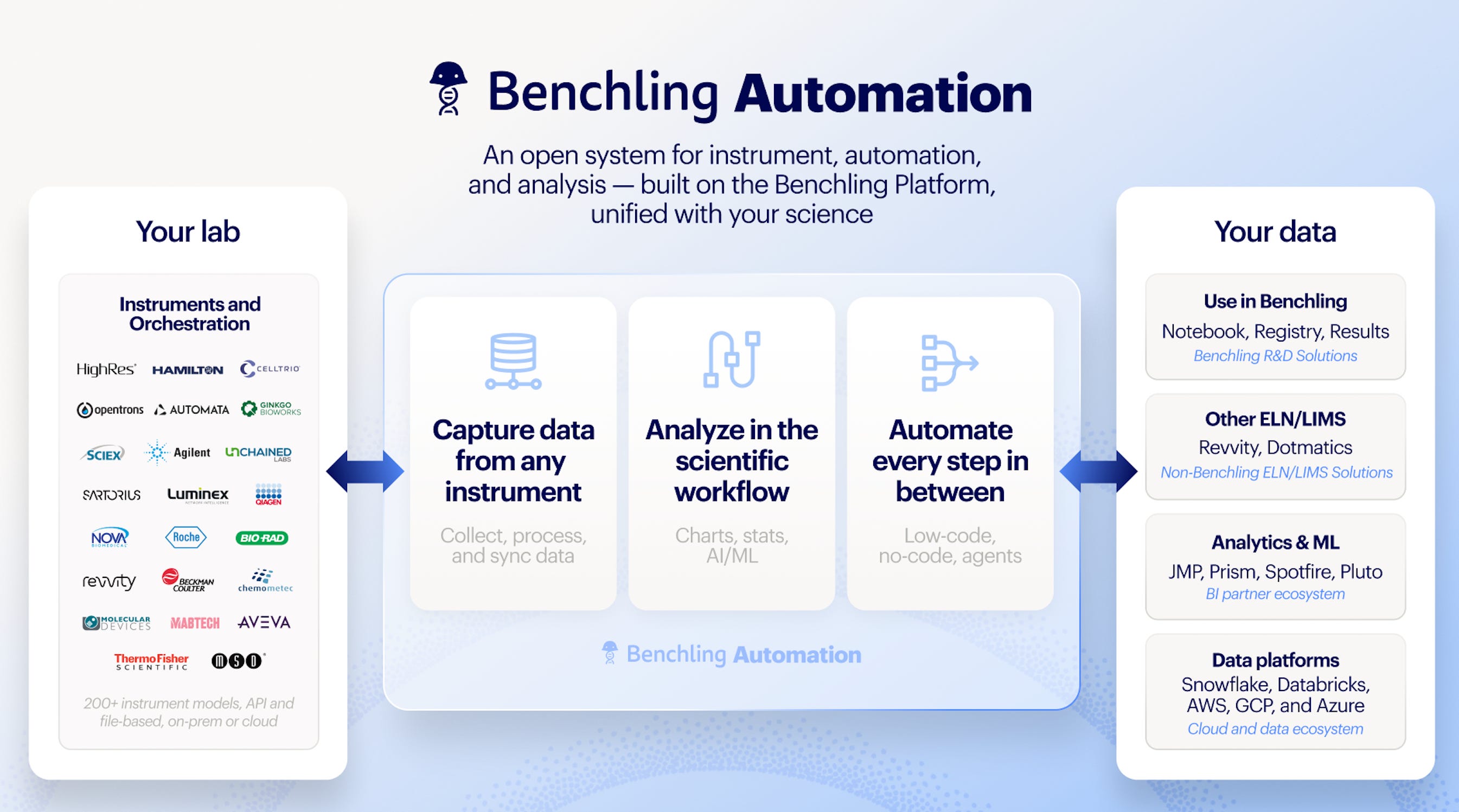
Benchling Automation. A hardware-agnostic layer connecting instruments and workcells to Benchling’s scientific record. Customers can pull data from 200+ instruments, design and own reusable workflows without custom code, write Python directly in Benchling, and land analysis back in the entry where the experiment lives.
Our guests
Ashu Singhal is co-founder and president of Benchling, which he started with Sajith Wickramasekara out of MIT in 2012. He has led the company’s engineering and product organization for over a decade and is now steering its AI roadmap, including the Model Hub, the Baseten and Lilly TuneLab partnerships, and the automation strategy.
Nicholas Larus-Stone is Benchling’s Head of AI agents. He studied computer science at Harvard and was a senior engineer at BenevolentAI, where he worked on retrieval over medical literature and clinical trial reports. He founded Sphinx Bio, a scientific data analysis platform that Benchling acquired in April 2025, and now leads Benchling’s agent work, including the Deep Research agent and the AI Scientist.

A Conversation with Benchling’s Ashu Singhal and Nicholas Larus-Stone
PART 1: FROM SYSTEM OF RECORD TO A SYSTEM FOR INTELLIGENCE
Zahra: Benchling spent a decade building a system of record for biotech R&D. In the last eight months you have shipped the Model Hub, inference, automation, AI connectors, and an AI Scientist. Walk me through how you decided to ship all of this, and in that sequence. Is this all part of the ELN product?
Ashu Singhal: For a decade we helped scientists capture, manage, and handle their lab data better. As the models got better, we realized how much toil sits on top of that data that we could solve. Scientists spend enormous time manually capturing data, aggregating it for reports, and analyzing it, and over the last year LLMs got good enough to automate a lot of that. So one focus of the AI roadmap is agents that take out the toil.
The second area is democratizing access to scientific AI models as a new tool for scientific work. Benchling’s history has often been about democratizing access to new techniques. Back in 2014, when CRISPR was becoming a bigger and bigger tool, we launched guide design very early in that trend, and tens of thousands of scientists ran their first CRISPR experiment with us. Structure prediction, property prediction, and generative models are becoming just as important, but they are too hard for the average scientist to access. That is why we built the part of the roadmap that makes those models easy to run.
Over the last few months, with those agents and models as a foundation and the underlying LLMs improving, we could unlock the next stage: a more end-to-end AI scientist.
Nicholas Larus-Stone: The interesting thing about what we have built over a decade is that we capture both the structured scientific data and workflows and the unstructured context around them. There are not many places that have both, and it is helpful for both halves of what Ashu described. If you have ever worked on a dry lab team, you know how hard it is to understand the nuances of the wet lab experiments, and those nuances actually affect the models you train and run inference with. Agents also perform much better with the right context. We are in a good position to provide that context, and that is the basis for why we have felt obliged to ship our own AI Scientist.
Zahra: How do you capture the unstructured contextual data? Is it mostly manual entry or has Benchling experimented with voice, vision or pulling directly off lab instruments?
Nicholas Larus-Stone: The notebook is where scientists record both what they plan to do and what they actually did, so it combines unstructured notes (”here is what I actually did, versus the protocol”) with structured data. That can be uploaded manually, but we have also spent years connecting into the lab and pulling data directly off instruments. More recently we have been bringing AI further into the lab, so scientists can talk to their notebook while they work. Voice is something we have been testing with a handful of customers. We have also experimented with vision, including smart glasses we demoed at Benchtalk last year, but the models are not as good there yet, so that is more of a preview until they improve. Voice has progressed enough that we are comfortable deploying it.
Zahra: You originally built the agents as a separate experience and then folded them into the notebook, and you went from multiple agents to one. What drove that?
Nicholas Larus-Stone: Two separate changes. On going from many agents to one: early on the models were not as good, and dedicated prompts and separate agents helped. But it created confusion. People would ask whether they should use the Compose agent to draft a notebook entry or the Deep Research agent to write a report. As the underlying models got good enough to do more, performance was actually better across the board with a single agent, so we unified them.
The second change is embedding it more deeply in the notebook. We heard a lot of “it is great that I can have this chat, but I am already in the notebook doing my daily work, and I want the agent to work with me here.” So the agent now works alongside you directly in the entry rather than as a chat off to the side.
PART 2: THE HARNESS, AND WHY VERTICAL BEATS HORIZONTAL
Zahra: Take me into the architecture of the AI scientist. How does it know which tools to call and how to interpret their results? If the agent runs two different structure prediction models, for example, and the outputs disagree, how does it resolve that?
Nicholas Larus-Stone: A lot of work goes into the harness, and building a good one is hard. What we have found is that more is better, across almost everything. It is true across LLM providers: the models from the different major labs have different strengths and weaknesses, so using them in parallel and in concert matters. It is true across search providers: for literature search, different providers surface different papers, and searching across several gives much better performance. And we think it is true across scientific models: if you can ensemble the best-performing structure predictors, you get something closer to truth.
Broadly, we are working in a domain that is intelligence-limited. Science is really, really hard, so the more we can do to push that forward, the better, and that requires us to be a fairly neutral party across all the LLMs, search providers, and model providers.
In the notebook, the agent works on top of an entry that already has the protocol and the structured results. You can ask it to analyze the data, and it retrieves any related data from other experiments, writes the code, runs the analysis, makes plots, and calls out its assumptions and caveats. You can then ask it to design the next experiment, say to maximize yield, and it produces the design as a new notebook entry, which is the artifact you actually take into the lab, either through automation or by hand. Once you have run several of these, you can aggregate across them. Building a report across a multi-month study, something that used to take days or weeks, now takes about twenty minutes.
Zahra: If you do not specify the model, does the agent have discretion over which one to use? And is it good at discerning discrepancies between model outputs?
Nicholas Larus-Stone: If a scientist wants to choose, they can; some people know they want Chai or Boltz for a given task. On the agent side, we delegate that choice to the agent. These LLMs have ingested the papers, so they have pretty good intuition about which model to choose, as long as they have enough context about your experimental setup.
Zahra: The system of record is clearly sticky on its own. If that is the durable asset, why build all the custom AI agents and harnesses on top? Why not leave the AI layer to an external party?
Nicholas Larus-Stone: Because no one has built the right agent, and we are well positioned to, since we understand both the shape of the data and the workflows scientists go through. There are enterprise chat clients like ChatGPT and Claude and their respective coding agents. In my opinion those are not the right agents to do novel scientific research. They are okay. I think we can do much better when we understand the tasks people are trying to do and the data model and tools we can give the agent.
Zahra: How do you evaluate whether the agent is picking the right tool and showing the right intuition? Are there evals you can point to?
Nicholas Larus-Stone: We are building evals from a combination of talking to customers, watching how they use it in production, and using real drug discovery program data to construct realistic tasks. A lot of public benchmarks target more academic tasks, like literature search and bioinformatics analysis, because that is where public data exists. Those are useful, but they do not capture the full complexity of what an industrial pharma company does day to day. So we spend a lot of time choosing the right tasks to build evals around, optimizing the harness for the real work rather than only the published benchmarks.
Zahra: The harness calls many models at once, and you run on consumption with a free tier. How do you think about cost and latency, and are you actually margin positive?
Nicholas Larus-Stone: On latency, most of our tasks are agentic rather than answer-oriented, so there is less pressure to respond in two seconds, and we parallelize across models and tool calls anyway. The way I think about cost is value, not spend: a wrong answer in five seconds is worse than a right answer in five minutes when someone is making a million-dollar call, so I tell people to spend ten minutes to save ten weeks rather than rerun the mouse experiment they did not know they had already run. On the economics, we track consumption across every model and agent, so we know the cost, and we are margin positive on AI usage. The value on top of the raw API calls is real, which is why we are comfortable charging above the raw token cost.
PART 3: DEMOCRATIZING THE SCIENTIFIC MODELS
Zahra: You mention democratizing access to biology AI models, but companies such as Latent Labs and Chai Discovery are building elegant UIs and agent interfaces of their own. As they do, where is Benchling’s advantage in democratizing access to models?
Ashu Singhal: Model makers vary a lot in how much they invest in their own products. The academic groups publish papers and open source and are not really building products. We also have a deep partnership with the Boltz team, who are building a high-performance API for accessing their models. Our view is that we would prefer to build less ourselves, so when something like the Boltz API comes out, we are happy to build on top of it.
But almost every scientist’s workflow involves chaining multiple models together. You use one model to generate an antibody sequence, another to predict its properties, and you iterate in a loop. Scientists need a single interface that aggregates those models. And the outputs are far more useful when chained directly with real wet lab data, so you can compare model output against experiment, or fine-tune your own model. Given our history on the wet lab side, that is what is unique about what we can offer.
Zahra: Right now the models on the hub are mostly structure prediction. Is there a plan to extend that to cover the full pipeline in drug discovery?
Ashu Singhal: Yes, that is the direction. We started with structure prediction because the open models matured there first, but one predictor is not a pipeline. The workflow is a loop: generate a candidate, predict its properties, rank it, repeat. So we have added generative models like BoltzGen through the Boltz partnership, and we are working on property and developability predictors, so the agent can run more of that loop instead of stopping at a structure.
Our partnership with TuneLab is the clearest example on the property side. Lilly trained those models on their own preclinical, ADME, and safety data across hundreds of thousands of molecules, which is exactly the downstream prediction a smaller biotech cannot build alone. It runs as federated learning, so a scientist gets the prediction inside Benchling and shares results back to improve the model without their proprietary data ever leaving. Lilly came to us to distribute it because we are where scientists already work and we hold the wet lab data that federated approach needs.
Zahra: How does this work as a business, both for Benchling and for the model providers? Is it pay-per-query? Do customers need their own subscriptions with model makers?
Ashu Singhal: All of our AI offerings go to market on a consumption-based model, with a free tier for every customer, because a big part of the mission is democratizing access. So many scientists do not know what is possible with AI right now simply because they cannot easily access it. For proprietary third-party models, we are starting to do revenue-share-style arrangements with the model makers. Open source runs entirely through us.
Zahra: You also recently partnered with Baseten to provide an inference offering. Why?
Ashu Singhal: As we brought the scientific models to market, we realized how uniquely bursty scientific model usage is compared to general AI usage. After you run a scientific model, you have to go into the physical lab and do something, like testing antibody candidates, which means stretches of time where you are not constantly running GPUs. You cannot just reserve a fixed number of GPUs for a period. We wanted to build on the best rather than solve the entire inference problem ourselves, and Baseten has an interesting approach that distributes inference across many GPU clouds. We use it internally for our own bursty workloads, and we are now taking it to market, because biotechs have their own internal private models that face the same bursty inference problem.
PART 4: READ AND WRITE, AND THE COMPOUNDING LOOP
Zahra: On the build-versus-partner question, where do you think Benchling really needs to own the advantage, and where can others build pieces you integrate?
Ashu Singhal: Two broad areas. The first is a harness that can intelligently read and write into the Benchling data model. I emphasize write, not just read. In the same way Claude Code or Claude Cowork write files on your local file system, it matters that the AI scientist saves its work back into the customer’s scientific record. A human scientist generates IP that makes the company smarter over time, and the AI scientist should too. That write-back is what makes each turn of the loop smarter.
The second is writing the Skills that package a company’s specific knowhow for the agent. Beyond the out-of-the-box Skills for data analysis and report writing, a lot of the real work in an engagement is defining a Skill that captures how a company thinks about assay development or validation. We spent a decade getting good at translating a customer’s science into the right data model. I think we will build the same muscle for translating it into the right Skills.
Zahra: Benchling recently published a case study with Prime Medicine. For such a customer, with years of data and many scientists running experiments, how do you measure whether the agent is actually learning in context from what is happening across that organization?
Nicholas Larus-Stone: I would look less towards memorizing and learning, and more toward whether it can find the right data for the right task. To some extent the eval for customers is simply: when I ask it to do something, does it do the right thing, and do I come back to it. A short anecdote: we worked with a large pharma company that had acquired many companies over the years. People from those companies had left, and their knowledge left with them, but the data of their past experiments remained. A scientist trying to decide on some in vivo experiments asked the agent to find what might have been done before. It pulled back the different mouse models that had been used and the experiments run on them, and the scientist realized he did not need to rerun twenty models, just two. That saved months and hundreds of thousands of dollars.
PART 5: CLOSING THE LAB-IN-THE-LOOP
Zahra: Let me turn to automation. What is the state of Benchling Automation today, and where is it headed? Is the vision for Benchling to talk directly to CROs and lab robotics companies?
Ashu Singhal: A couple of years ago we launched Benchling Connect, focused on capturing instrument data and structuring it. There is a cross-industry consortium, the Allotrope Foundation, that has worked for years on best practice data models for different instruments, but they have never had the library of parsers. Our Connect offering included open-source parsers from many instrument types into the Allotrope model. We open-sourced them because we kept seeing companies reinvent the wheel on instrument data capture, and we wanted the industry to adopt a standard.
As that gathered steam, we also saw a large hardware investment from customers building end-to-end automated setups, often for lab-in-the-loop, where automated workcells run experiments generated by models and the resulting data trains the next model. So late last year we started building out-of-the-box integrations not just to individual instruments but to whole workcells. We announced a partnership with HighRes, one of the major workcell builders. The goal is to cut the custom work involved in standing up a new automated lab, and to make those setups flexible as workflows change. The final piece is bringing that same integration approach to CROs. Some companies, rather than investing in internal workcells, are running more orders externally with companies like Twist. So you can automatically kick off an order and bring the data back, whether the other side is a workcell or a CRO.
Zahra: Can you help me visualize what that looks like, from a scientist submitting an automation job to what comes back?
Ashu Singhal: A customer configures a pipeline that covers both what information should be sent to, say, HighRes, and importantly how the returned data should be analyzed, including any curve fitting or processing. Once it is configured, a scientist can execute that pipeline from within a notebook entry. They press a button, the data is sent, the assay data comes back, and it is processed automatically. The step we are adding now is making that entire pipeline a tool that an agent can call, which is what enables more augmented loops, where the AI scientist makes choices about which samples to push forward rather than a human deciding every time.
Nicholas Larus-Stone: That piece matters because there is a spectrum. On one end is the high-throughput, well-structured assay you push through a workcell. On the other is the thing you do once, by hand, and record yourself. A lot of work lives in the messy middle. We do not think the best solution there is AI just yoloing and potentially wasting tens of thousands of dollars of reagents. It is some combination where the AI has the non-determinism to assess the available pipelines and workflows and choose the right one, but executes it in a deterministic manner. You get much less risk of doing something completely wrong and hallucinated, while keeping the flexibility that traditional automation has struggled with.
PART 6: THE MOAT, AND THE HUMAN IN THE LOOP
Zahra: Since customers own their data, Benchling AI can reason over one customer’s data but cannot learn across all of them to build one better model. Take AlphaSense as a contrast: their moat is aggregating equity research from every bank, with the licenses, so the AI can reason over all of it. You cannot do that with proprietary biology. Does that put Benchling at a disadvantage?
Nicholas Larus-Stone: We do not train across customers, and honestly I do not think that is a Benchling-specific thing. I do not think any biotech will tolerate cross-customer training; everyone has zero-data-retention policies with their AI vendors. The Lilly TuneLab partnership is the interesting middle path, where federated learning lets the industry benefit without leaking data, and you can imagine more of those initiatives over time.
But the bigger point is that there is less to learn cross-customer than you would expect. Some things are universal, and those can usually be found in the public literature. Where companies differentiate is in their science, and they are usually doing something fairly unique, which is exactly where the interesting work happens. So it is not clear that pooling everyone’s data would be immediately useful anyway.
Zahra: The other version of that question: big labs are betting their models get good enough to read messy notebooks directly. Could someone just point an AI agent at a pile of notebook PDFs and skip the structured system of record?
Nicholas Larus-Stone: It is a fair question, because AI feels like it can do anything. Our AI can certainly search over the unstructured data in notebooks. But it is clearly better to have structured data, and it is more accurate. You would much rather have a SQL query return results than have an LLM read hundreds of notebook entries. It is faster, and it is cheaper, and cost is becoming more important. Better, faster, and cheaper is generally pretty good, which is why we are optimistic that structured data stays valuable.
Zahra: Could this become a future where agents do most of the science themselves, spotting a pattern in a dataset and running the follow-up experiments without the scientist’s input?
Nicholas Larus-Stone: We are seeing the world move in the direction of agents handling individual tasks and removing the white space, and we think that is good. Where we do not see agents replacing people anytime soon is scientific judgment. Agents are good at data analysis and at proposing hypotheses, including from literature and data you were not aware of, but the scientist looks at those and applies judgment, and that is much better than an agent alone. So humans stay an important part of the loop. They can just do far more. A small team can push a whole drug discovery program that used to take dozens of people, so each scientist gets a lot more leverage.
Zahra: And in the wet lab specifically, are humans indispensable, or could automation fully close that loop?
Nicholas Larus-Stone: A blend. Some assays you want to run at high throughput and can fully automate. No one has cracked a really flexible automated lab, and humans are excellent generalists who pick things up on the fly across many instruments. So you want a system that accounts for both: it knows what equipment you have, suggests running this part on your automated setup, and flags that this other variant is not automated yet and needs someone in the lab.
Zahra: Where do you see the biggest sources of friction in expanding this vision?
Ashu Singhal: A huge piece is helping customers adopt the technology. The capabilities of these models are far ahead of what the average scientist is able to use today. That is why we have always invested in services, not just software. We were doing forward-deployed work before it was cool, and roughly a third of the company is scientists who used to be at the bench, who help customers figure out the right data model and how their workflows should change. That last-mile change management is even more important with AI, because it is a bigger change to how science gets done.
Nicholas Larus-Stone: On the technical side, the two big challenges are being specific to someone’s science and interfacing with the physical world. Most people’s science is not public; they may have worked on something for years that has nothing close in the literature, which limits both what LLMs and scientific models can do, since they often do not generalize to genuinely novel work. That is why the right context and data to fine-tune and to provide in-context learning matters so much. And the physical world is hard. Biology is complex, and lots of things go wrong when you run the experiment, so the systems and agents have to be robust to all the challenges of translating something into the real world.
Zahra: Last one. Where do you wish someone would build, in a way that would help Benchling’s mission, that Benchling is not going to build?
Ashu Singhal: Better models in general, better scientific models and better foundation models, because they make the work scientists do through our platform that much better. And better integrations into instruments. A nice Python layer on top of instruments would be a lovely thing if we did not have to build it ourselves.
Zahra: A good message for future builders. Thank you both, and congratulations on the launches.