

BioByte 142: Addiction Treatment with GLP-1s, Engineering Cement-Making Microbes, and Leveraging GigaTIME to Study Tumor Immune Microenvironments




Welcome to Decoding Bio’s BioByte: each week our writing collective highlight notable news—from the latest scientific papers to the latest funding rounds—and everything in between. All in one place.

Dewey Albinson, Cement Works (1933)

What we read
Blogs
Will blockbuster obesity drugs revolutionize addiction treatment? [Elie Dolgin, Nature News Feature, December 2025]
Stories about people struggling with substance use disorders, such as opioid, cigarettes, cocaine and alcohol addiction, who have managed to become drug-free for the first time after starting GLP-1 treatments have been spreading rapidly in recent years.
Earlier this year, Christian Hendershot, a psychologist at USC, reported that weekly injections of semaglutide reduced alcohol consumption:
Semaglutide treatment did not affect average drinks per calendar day or number of drinking days, but significantly reduced drinks per drinking day (β, −0.41; 95% CI, −0.73 to −0.09; P = .04) and weekly alcohol craving (β, −0.39; 95% CI, −0.73 to −0.06; P = .01), also predicting greater reductions in heavy drinking over time relative to placebo (β, 0.84; 95% CI, 0.71 to 0.99; P = .04).
In 2015, a team of researchers uncovered the first evidence of the connection between GLP-1 and alcohol dependence, where there was a common variant of the GLP-1R gene was linked to heavier drinking. The same team used post-mortem brain tissue and discovered that GLP-1R expression was elevated in reward-related regions of the brain.The mechanistic hypothesis is that alcohol dampens the body’s GLP-1 production, so the brain boosts expression of the hormone’s receptors “to preserve sensitivity to the hormone that govern reward and emotion”.
However, since then, the first slew of trials with first-generation GLP-1 therapies like exenatide and dulaglutide did not have an impact on alcohol or smoking dependence. One study, however, involving people with opioid-use disorder saw a 40% reduction in cravings with liraglutide.
Second-generation GLP-1s are much more potent, so these could lead to better results. There are several trials in progress, testing high dose semaglutide for alcohol-use disorder; reading out next year. Eli Lilly, for instance, has launched a 300 person trial to test tirzepatide for the treatment for alcohol-use disorder.
You Gotta Make It ‘Til You Make It [Lee, Off the Media, December 2025 (based on original paper by Ortiz et al., bioRxiv, December 2025)]
Cement production is responsible for roughly 8% of global emissions. Creating lower-carbon alternatives that match its strength and durability is a pressing priority for decarbonizing the built environment. Microbially-induced calcium-carbonate precipitation (MICP, or biocement) — where bacteria convert urea and calcium into a calcite that glues soils and aggregates into stone-like material — promises low-temperature, low-carbon alternatives if we can reliably control the microbes producing the material. Until now, progress has been limited because the most widely used biocement microbe, S. pasteurii, was not genetically modifiable. This effort by the Cultivarium moves the needle from process engineering to more rational biology: by delivering the first genetic toolkit for S. pasteurii, the authors unlock routes to tune urease activity, reduce ammonia byproducts, and engineer crystal formation and sporulation for industrial deployment.
Ortiz et al. built and validated a robust genetic stack for S. pasteurii: a working replicating plasmid and conjugation protocol, characterized constitutive and inducible promoters spanning 3 orders of magnitude of expression, fluorescent reporters and selectable markers, and a genome-wide transposon library (>15k unique insertion sites covering ~92% of genes). As functional proof, they precisely deleted the 5.7kb urease cluster, which abolished urease activity and biocement formation. Moreover, their transposon screen revealed unintuitive hits, such as a transporter knockout that improves growth on urea. Crucially, the authors’ breakthrough stemmed from mining an environmental relative that tolerated the plasmids and then porting functional parts back into the canonical strain — a generalizable strategy for unlocking intractable organisms and accelerating platform development across non-model microbes.
Many translational steps remain — ranging from validating engineered strains in field-relevant complexes (saline soils, agricultural waste, variable pH) to designing biocontainment and regulatory pathways. If these milestones are met, biocement may become an economically competitive, greener complement to conventional materials — and an encouraging signal of biology’s potential to resolve enduring materials and manufacturing challenges.
Papers
Multimodal AI generates virtual population for tumor microenvironment modeling [Valanarasu et al., Cell, December 2025]
Why it matters: The new GigaTIME model aims to accelerate research of Tumor Immune Microenvironments (TIMEs) by leveraging machine learning to generate information-rich multiplex-immunofluorescence images from H&E histology slides. The model was tested on its ability to correlate these generated proteomic landscapes with clinical outcomes based on biomarker, staging, and patient survival data. GigaTIME’s performance on virtual populations shows the potential of such approaches to overcome data limitations to provide potentially actionable insights into TIME behavior and associated clinical outcomes.
Cancer is defined not just by the aberrant cells gone haywire, but the larger tumor immune microenvironment (TIME) in which they exist. Tumor microenvironments are dynamic ecosystems of both cancer and non-malignant cells like immune cells, fibroblasts, and endothelial cells. The study of TIMEs can take place at varying resolutions, with some approaches like immunohistochemistry (IHC) reporting on individual protein expression levels at a single timepoint and sample. More high-throughput alternatives exist like multiplex immunofluorescence (mIF), which can enable multi-channel protein profiling on a single tissue sample, albeit with considerable increases in experiment and general infrastructure costs which limit scalable adoption. However, one of the most abundant, clinically-derived pathology data sources are hematoxylin and eosin (H&E) images which can record tissue structure and cell morphology, but do not explicitly report on cell states. In this paper, a team of scientists from Microsoft Research and their academic partners describe the development of GigaTIME, a “multimodal AI framework that enables population-scale TIME study by learning to generate virtual mIF images from readily available H&E images,” making a bet that machine learning can bridge highly informative, but rare mIF data with widely available H&E imaging for scalable TIME modeling and potential advances in precision immuno-oncology.
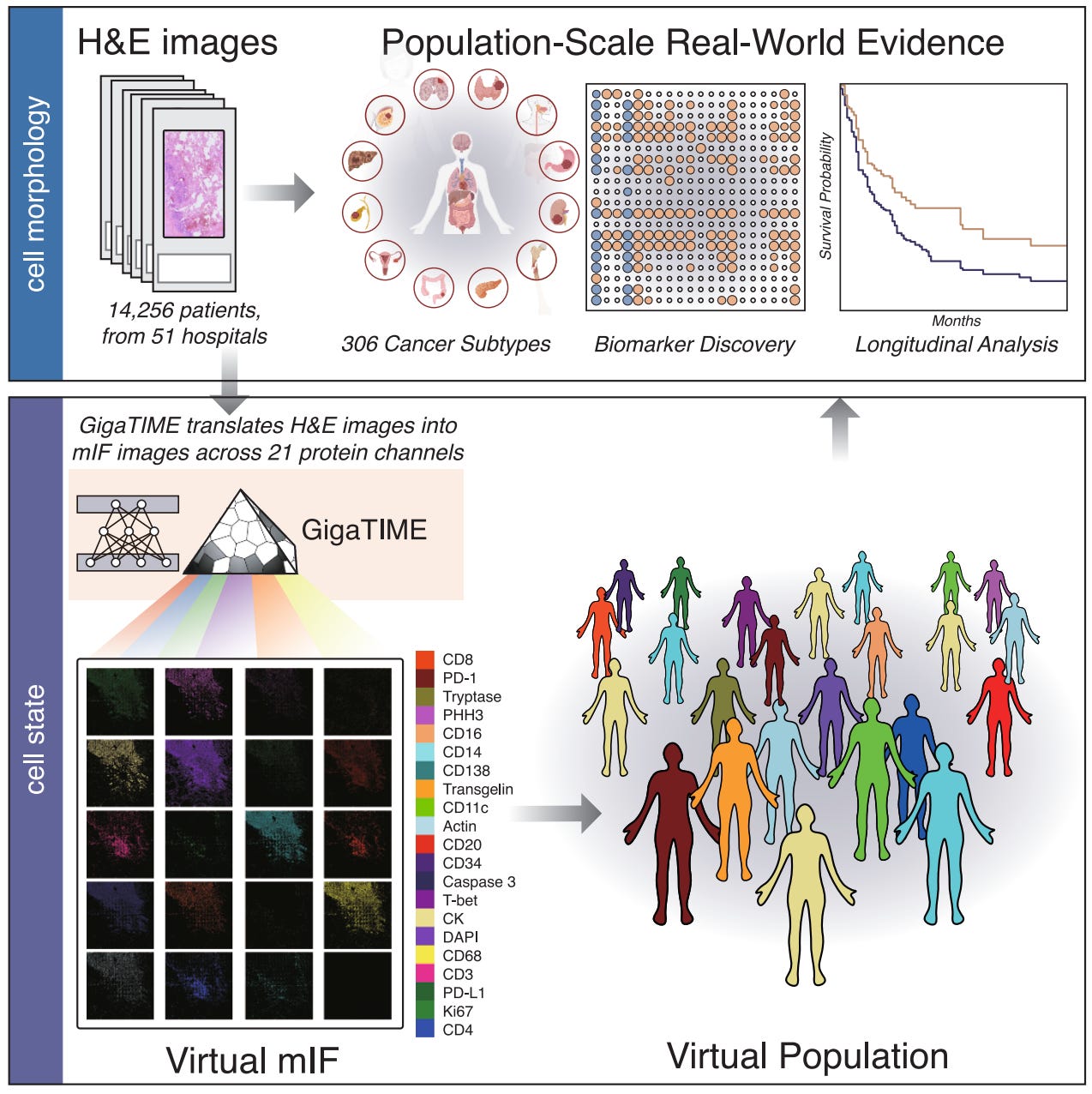
Briefly, GigaTIME was trained to generate miF images from H&E stained input slides, specifically focusing on predicting 21 protein channels. The authors experimentally acquired over 400 mIF images from H&E-stained slides and then used the paired dataset to train a NestedUNet based model that takes H&E image patches as input and outputs 21 mIF patches. These patches were combined to reconstruct whole-slide mIF images (where each pixel had a binary label for the presence or absence of each of the 21 protein channels) based on the underlying cellular morphology and spatial structure present in the H&E input. The authors first benchmarked GigaTIME’s ability to generate realistic mIF images, comparing the model to the widely used image translation model CycleGAN. GigaTIME was able to match or outperform CycleGAN on nearly 70% of protein channels, and most importantly, showed far more promising performance on recapitulating cell-level patterns rather than just pixel level details.
After ascertaining that the model could in fact generate realistic mIF images, the authors used GigaTIME to generate a “virtual population” that combined generated mIF images with information about biomarkers, staging, and patient survival information. Using patient data from over fifty hospitals and over 1000 clinics in the US, the team generated nearly 300 thousand miF images spanning over 14 thousand patients and over 300 cancer subtypes. This massive dataset was used for a variety of population-scale clinical discovery challenges. Notably, the team was able to identify increasing numbers of statistically significant TIME protein-biomarker associations as they studied pan-cancer, cancer-type, and subtype specific cohorts. Interestingly, pairing the generated images with clinical information showed promising results on predicting staging and survival information, especially when compared to such analyses with a single protein. This pattern of analysis was also used to discover proteins that seemed to have a synergistic association for predicting disease outcomes, with the authors noting that the CD128 and CD68 protein channels showed better performance when used together for predicting clinical biomarkers, once again in comparison to any individual other protein. Finally, GigaTIME was also applied to the larger Cancer Genome Atlas (TCGA), and a virtual population was created based on the over 10,000 tumors within. The team found that there was a high level of correlation between the hospital and clinic data they had been working with and the TCGA cohorts, but the former virtual population was able to “[yield] more significant associations than TCGA,” pointing to the importance of diverse data sources.
In summary, GigaTIME shows the promise of integrating rare, but highly informative data sources like mIF with more widespread H&E images to produce accurate models of the TIME and connect that to clinical information. The authors note that further development will include a patient dataset that is more geographically and ethnically diverse to better capture information from under-represented populations. Additionally, they also note the importance of testing additional protein channels to capture more information from slides. It will be interesting to see how continued data generation efforts help the development of tools like GigaTIME, as well as how such models evolve with the potential use of alternate machine learning frameworks.
Notable deals
The San Diego-based BlossomHill Therapeutics raised $84M for their Series B extension, adding to the $100M raised in their Series B in February of 2024. The funds will be used to advance the company’s two oncology programs, both currently in early clinical trials. BH-30643 is an orally-available macrocycle designed to address a diversity of mutations in the EGFR kinase domain. Currently in Phase I/II, BH-30643 has already shown CNS anti-tumor activity across historically drug-resistant mutations in preliminary data. The other program, BH-30236, is also an orally-available macrocycle, but serves as an inhibitor of CDC-like kinase (CLK). It is being evaluated as both a monotherapy and with venetoclax in Phase I/Ib trials. Significant data from both programs are expected in 2026. The round was led by Brahma Capital, BioTrack Capital, and Janus Henderson Investors with additional support from Cormorant Asset Management, OrbiMed, Plaisance Capital Management LLC, and Vivo Capital.
PsiThera announced their $47.5M Series A—led by Lightstone Ventures and Samsara Biocapital—alongside the appointment of their new CEO. Guided by their QUAISAR™ platform, the company’s initial programs are focusing on the Tumor Necrosis Factor (TNF) superfamily. The QUAISAR™ platform leverages the insights derived from quantum chemistry and molecular dynamics simulations in tandem with AI to elucidate actionable insights from an understanding of the movement of drugs and proteins within the body. Their platform has already enabled them to dramatically accelerate their development timeline, bringing a novel scaffold from hit to lead optimization in just four months. Other investors in the round included Eurofarma Ventures, Roivant (which the company spun out from), and YK Bioventures.
The rare disease company Mirum Pharmaceuticals entered into a definitive agreement to buy Bluejay Therapeutics. Mirum, which already has several rare liver disease programs, would acquire the rights worldwide to Bluejay’s brelovitug, a monoclonal antibody in Phase III trials for chronic hepatitis delta virus (HDV) with Breakthrough Therapy and PRIME designations. The asset performed well in Phase II trials, achieving 100% HDV RNA response and exhibiting a favorable safety profile. Its addition to Mirum’s portfolio would serve to strengthen their leadership in liver rare disease. The deal will net Bluejay $250M in cash, $370M in Mirum common stock, and a potential additional $200M in milestone payments. Subject to regulatory approval, the deal will proceed in early 2026, as both boards have already agreed.
Formation Bio has agreed to license LNK01006 from Lynk Pharmaceuticals, developing the asset in their new subsidiary Bleeker Bio. LNK01006 is a highly selective, allosteric TYK2 inhibitor—and potent CNS penetrant—which has recently received IND clearance for first-in-human studies in the US. The drug is a powerful immune response regulator with potential applications in a number of inflammatory and autoimmune diseases. From the deal, Formation obtains the rights to develop and market the drug worldwide, excluding Greater China, while Lynk will receive up to $605M in upfront payment and milestones. Lynk also will be granted a minority stake in Bleeker Bio.

What we listened to
What we liked on socials channels



Field Trip
Did we miss anything? Would you like to contribute to Decoding Bio by writing a guest post? Drop us a note here or chat with us on Twitter: @decodingbio.