

BioByte 138: Understanding Codon Translation with EnCodon, LabOS AI-XR Co-Scientist Assists in Wet Lab, Pearl Outperforms AF3, and the Brain's Predictive Immune Response to Infectious Visual Cues




Welcome to Decoding Bio’s BioByte: each week our writing collective highlight notable news—from the latest scientific papers to the latest funding rounds—and everything in between. All in one place.

Stars by Wassily Kandinsky, 1938

What we read
Blogs
Introducing Pearl: The Next Generation Foundation Model for Drug Discovery [Genesis Research Team, Genesis Molecular AI, October 2025]
Accurately predicting how drugs bind to protein targets has been the holy grail of computational drug discovery. Genesis takes a significant step toward that goal: with Pearl, a protein-ligand structure prediction model, they surpass AlphaFold3 – achieving 14-15% relative improvements on standard RMSD-based benchmarks (PoseBusters and Runs N’ Poses) and substantially larger gains (3.6x at sub-angstrom accuracy) on proprietary, real-world drug targets. Beyond the headline numbers, Pearl’s explicit design for deployment is noteworthy: the model trains on large-scale synthetic complexes generated via physics simulations to overcome data scarcity, uses an SO(3)-equivariant diffusion architecture that enforces 3D rotational symmetry and geometric consistency in its predictions, and provides ‘scientist-in-the-loop’ control through templating and conditional inference modes enabling chemists to steer predictions with auxiliary structural information.
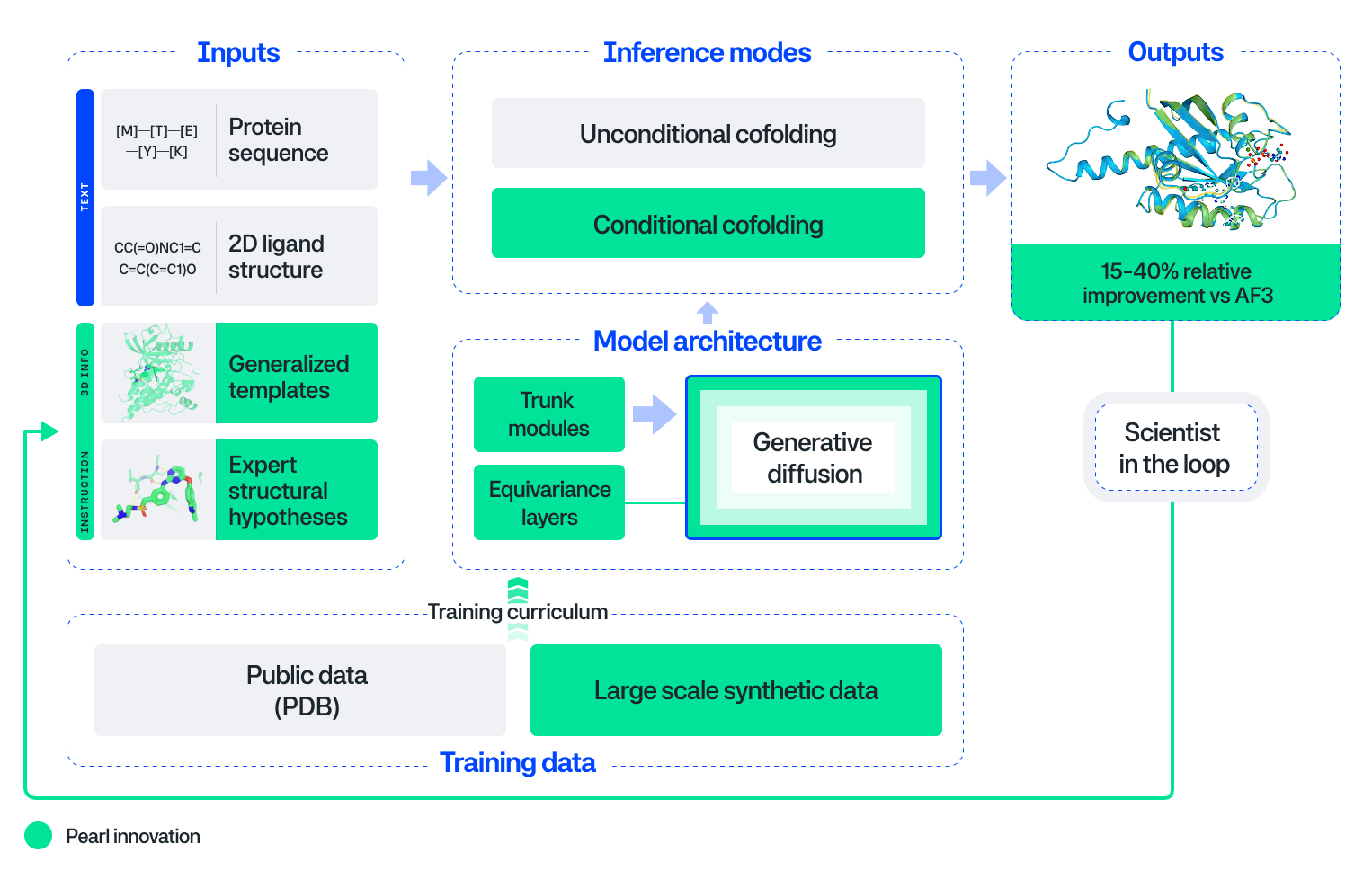
The technical choices reflect pragmatic engineering for drug discovery workflows rather than pure benchmark optimization. Training on synthetic physics-generated data is presented as a viable strategy – the team demonstrates that model performance scales monotonically with synthetic dataset size, suggesting a potential concrete path to improvement beyond the limited corpus of experimental structures. The conditional co-folding interfaces and templating system address a common failure mode of generative structure models: a lack of actionable control. Pearl allows chemists to leverage known binding pocket information or related crystal structures to generate and sample physically plausible poses they can iterate on – critical for lead optimization where sub-angstrom accuracy correlates with potency prediction. Importantly, the team demonstrates that standard <2Å accuracy thresholds are insufficient: qualitative analysis reveals that many poses below this threshold contain critical issues ranging from ring flips to missed interactions, rendering them spurious models for medicinal chemists.
The work comes with measurable caveats crucial to adoption in drug discovery. Reliance on proprietary and physics-generated training data raises questions about out-of-distribution robustness and whether synthetic priors fully capture binding thermodynamics – the associated paper itself catalogs common failure modes and emphasizes that high-accuracy thresholds are necessary for discovery utility. Moreover, independent validation will offer more decisive information on the model: blind prospective tests on withheld industrial targets, comparative analyses in drug programs, robust uncertainty calibration to inform chemists when predictions warrant experimental validation. Most notably, the team demonstrates that confidence models across all evaluated systems failed to rank poses better than random selection, meaning reliable pose selection remains an unsolved problem. Nonetheless, Pearl’s clear gains in generation quality, scientist-in-the-loop controls, and scalable synthetic-data may shift structure-based modeling from a validation tool to a driver of lead optimization and expand the universe of tractable therapeutic targets.
Papers
Learning the Language of Codon Translation with CodonFM [Darabi et al., preprint, October 2025]
Why it matters: While there has been significant effort to develop foundation models for DNA and protein modalities, such models struggle to capture the relationship between codon redundancy and consequent molecular phenotype. Specifically, while the same amino acid can be encoded by different codons, the use of different codons can have significant downstream effects on translation, RNA stability, and protein expression. In this joint effort by scientists at NVIDIA, UC Berkeley, Stanford, and the Arc Institute, the authors describe the development of the EnCodon model, calling it a “scalable foundation for modeling translation and RNA-driven gene regulation,” with potential applications to mRNA therapeutics and vaccine development.
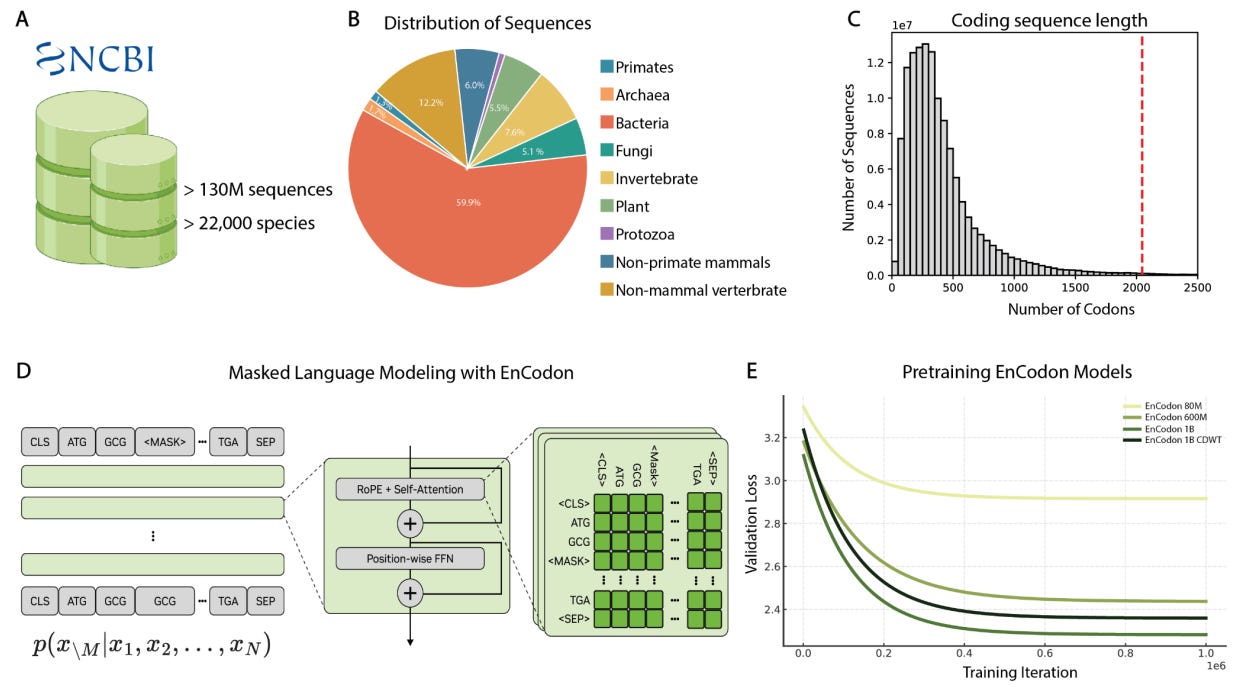
At the heart of the central dogma of biology is the flow of information and function from DNA to proteins using a host of RNA intermediates. Briefly, a series of three consecutive mRNA positions known as codons direct the binding of transfer RNA (tRNA) molecules that are bound to amino acids. These amino acids are strung together to form a diverse range of functional proteins. This codon-amino acid relationship has some inherent redundancy, with 18 of the 20 canonical amino acids being linked to more than one codon. However, not all codons are created equal! Research has shown that while a protein might have the same amino acid sequence, the use of different codons has been linked to “organism-specific and even tissue-specific signatures across species” with some variants being implicated in disease. To that end, current DNA and protein models are unable to reflect the relationship between codon-usage and resultant phenotype.
To address this gap, the authors developed the EnCodon model series within the CodonFM model family with the goal of understanding the “contextual grammar of codon usage.” The models were trained on over 130 million coding sequences from over 20 thousand species in the NCBI RefSeq/Genomes database. Sequences were tokenized at the codon level rather than nucleotide resolution to faithfully represent “codon-context relationships within open reading frames (ORFs).” This process yielded a diverse set of sequences spanning major phylogenetic groups with varying codon redundancy, GC content, and translation-associated sequence features. EnCodon was built with a transformer encoder architecture that is trained to predict masked codon tokens. The authors also investigated potential scaling law behavior, training model versions ranging from 80 million parameters up to 1 billion parameters, while also testing a masking strategy based on the relative usage of codons. To judge the quality of the learned representations, the authors looked at the models’ confusion matrices and found a reliable decrease in normalized scores as model size increased. This indicated that larger models are able to more effectively distinguish between codons when predicting masked tokens in different contexts. Furthermore, UMAP clustering of PCA-reduced embeddings demonstrated that models were able to learn codon-usage patterns across phylogenetic groups, with larger models showing significant improvements in clustering-space separation. Smaller model predictions demonstrated the highest correlation with fundamental amino acid properties like hydrophobicity while larger models “balance[d] biochemical features with additional contextual signals related to codon usage.”
The authors then evaluated EnCodon’s performance on a suite of variant effect prediction tasks, specifically looking at the model’s ability to classify mutations in developmental disorder and autism spectrum disorder cohorts. EnCodon surpassed unsupervised protein and RNA models and showed the greatest separation between control and case variants. EnCodon was also evaluated on the ClinVar missense variants dataset as well as somatic mutations in cancer. While the model did show promising performance and surpassed all RNA baselines, it did lag behind the ESM2 protein language model family. However, a fine-tuned EnCodon model did show comparable performance to the AlphaMissense protein pathogenicity model, even in the absence of any structural information. Notably, EnCodon was able to distinguish between missense mutations and benign synonymous variants with greater performance than all RNA and mRNA baselines. This task demonstrates the benefits of codon-level modeling given the historically challenging nature of resolving synonymous variant effects. Finally, a random forest regression over EnCodon embeddings showed that the model could meaningfully predict mRNA translation efficiency and protein expression, with significant gains over nucleotide resolution models.
While EnCodon will certainly need accompanying biological validation to demonstrate the end-to-end utility of its predictions, its codon-level modeling is an interesting approach to resolve the finer details underlying the central dogma and variant effect. The authors point to the inclusion of perturbation assays, explicit secondary structure dynamics, and tRNA abundance data as modes for improvement. Hopefully, continued improvements in this vein of modeling may aid downstream therapeutics and mRNA vaccine development efforts.
LabOS: The AI-XR Co-Scientist That Sees and Works With Humans [Cong et al., bioRxiv, October 2025]
Why it matters: Many works in the past year have refactored AI agent systems to act as scientific agents, performing the scientific loop of proposing hypotheses, generating experimental protocols, performing computational analysis and so forth. Cong et al. bring this system from inside the computer one step closer into the lab as AI co-scientists - an AI system that not only acts as a digital scientific agent, but also as a set of eyes that can guide and critique real-world wet lab experiments.
This work is grounded in two recent works from Le Cong’s group at Stanford to build AI that can augment the scientific process. First is their self-evolving scientific agent STELLA, which similarly to Biomni, mines scientific literature to build new tools that can be used by STELLA itself through tool use, and enable more effective computational analysis and protocol generation. Second is CRISPR-GPT, an AI system that guides protocol generation, computational analysis, and Q&A specific to CRISPR-related experiments.
To bring this into a real scientific environment, the authors use XR/VR glasses and vision language models (VLM) to understand, instruct, and critique scientists conducting wet-lab experiments. They use these glasses as the “eyes” of the system, streaming egocentric lab footage to an AI backend built primarily from the Qwen-VL model family, which serves as the visual cortex for scene understanding and reasoning. They record over 200 real experimental sessions, each minutes long, and have 5 human experts annotate every step, timestamp, and mistake to construct the LabSuperVision (LSV) dataset, a benchmark for evaluating AI understanding of laboratory procedures.

Armed with this benchmark, the authors test leading multimodal models (Gemini 2.5 Pro, GPT-4o, Qwen-VL, Cosmos-1) on their ability to infer which protocol is being performed and to identify procedural errors from the videos. Finding substantial performance gaps, they fine-tune and reinforce-train the Qwen-VL models using supervised and GRPO reinforcement learning to better capture procedural accuracy, safety, and temporal consistency - improving their lab reasoning ability, though not yet conclusively outperforming the strongest closed-source models. They also demonstrate LabOS’s dry-lab capabilities by generating new hypotheses in cancer immunotherapy (e.g., nominating CEACAM6 as an NK-cell target) and molecular biology (e.g., identifying ITSN1 as a cell-fusion regulator), largely extending the computational reasoning engine of STELLA into full research cycles. While these examples mostly highlight LabOS’s analytical power rather than its XR/VR copiloting features, the system as a whole marks an exciting step toward integrating AI into the physical workflows of science—augmenting scientists at the bench with real-time visual guidance, feedback, and knowledge transfer.
Neural anticipation of virtual infection triggers an immune response [Trabanelli et al., Nature Neuroscience, May 2025]
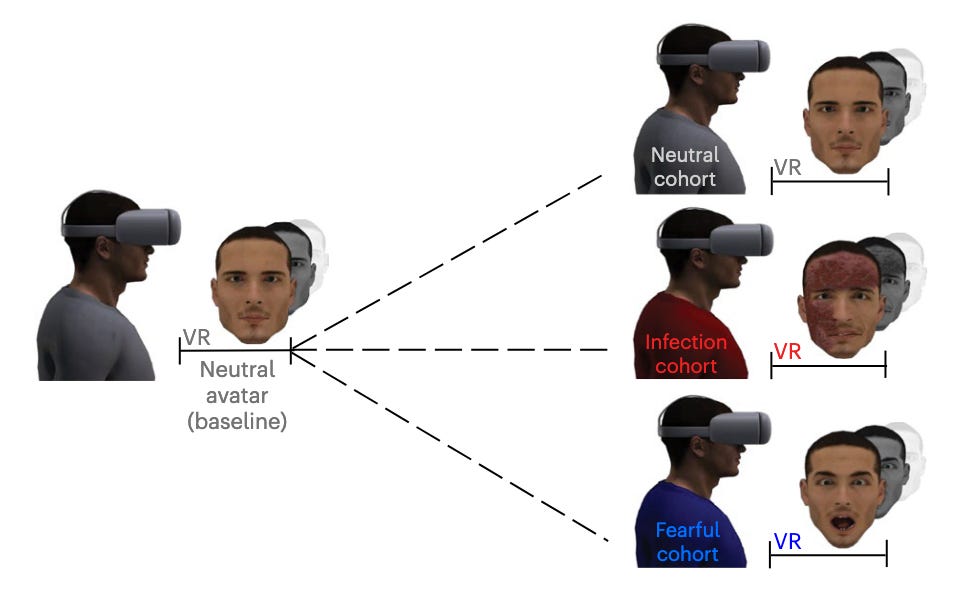
Why it matters: Can the brain pre-empt an infection before contact and proactively tune the immune system? We understand that our physiology changes upon detection of a physical threat, but the link between anticipation of an infection and the innate immune system response remains largely unexplored.
This group decided to explore the link between the breach of the participants’ peripersonal space (PPS) boundary by a virtual infection cue, and the innate immune system reaction via the use of VR by simulating infectious faces that loom toward the observer.
The results demonstrated that ‘potential contact with virtual infection threats is predicted by fronto-parietal areas of the PPS system’, triggering a cascade of neuro-immune modulators, ultimately inducing changes in innate lymphoid cell (ILC) frequency and activation. Infectious VR avatars generated an increase in ILC activation that was similar to that generated by vaccines, and higher than fearful VR avatars and the control group with neutral avatars.
Notable deals
Curve Biosciences brings in $40M funding round led by Luma Group to advance the clinical validation of their Whole-Body Intelligence Platform. Seeking to address chronic diseases through advanced detection, Curve has curated the Whole-Body Atlas, the world’s largest collection of tissue samples classified by organ and disease. The Atlas serves as the foundational biological truth for their Whole-Body Intelligence platform, a model trained on the biomarkers found in the numerous diseased tissue samples the company has collected. Insights from the model inform Curve’s Whole-Body Blood Tests, where relevant biomarkers are used to accurately and precisely identify chronic diseases. The round had additional participation from firms including Civilization Ventures, First Spark Ventures, Incite, LifeX Ventures, Micah Spear, Mintaka VC, NZVC, and Techas Capital.
The clinical-stage Hemab Therapeutics announces their $157M Series C led by Sofinnova Partners. Hemab—which is devoted to prophylactic therapeutics for serious, underserved bleeding and thrombotic disorders—will use the funds to put Sutacimig through its Phase II trial in Glanzmann thrombasthenia. The round will also cover registration studies for Sutacimig in Factor VII deficiency and HMB-002 in Von Willebrand Disease. Their earlier stage programs will also benefit, with the announcement of HMB-003 to be expected in the first half of 2026. Other investors in the round include Access Biotechnology, Avoro Capital Advisors, Avoro Ventures, Deep Track Capital, HealthCap, Invus, Maj Invest Equity, Novo Holdings, RA Capital Management, and Rock Springs Capital.
Zag Bio emerges from stealth with an $80M Series A, hoping to use the funding to put a candidate into Phase I next year. With their unique thymus-targeting platform, Zag is using regulatory T-cell therapies (Tregs) to address autoimmune diseases in a new manner, zagging while the rest of the autoimmune space zigs. In the thymus, their antigens leverage the body’s natural mechanism for T-cell tolerance to promote antigen-specific Tregs while reducing antigen-specific T effector cells. Zag’s emergence from stealth closely follows the recent Nobel Prize in Physiology or Medicine, awarded to three scientists who worked extensively on Tregs. Polaris Partners—who both founded and incubated the company—and T1D Fund led the round, with additional participation from pharma behemoths AbbVie, Regeneron and Sanofi.
GSK agrees to pay up to $745M to Empirico for the rights to develop and commercialize EMP-012, Empirico’s chronic obstructive pulmonary disease (COPD) drug. The asset is currently in Phase I trials for COPD, but GSK hopes to broaden its usage to other inflammatory respiratory diseases. The deal comes with an upfront payment of $85M, with the potential for another $660M in development, regulatory and commercial milestone payments. Aside from the payments, the deal is helpful for Empirico, who says the agreement provides strong evidence as to the capabilities of their target discovery and siRNA platforms. In July of this year, GSK picked up another COPD asset from China’s Hengrui Pharma.

In case you missed it
Launch of SeqHub by Tatta Bio: an AI-enabled platform for biological sequence analysis. SeqHub brings together sequence search, genome annotation, and data sharing in one place
Introducing BoltzGen: a new generative model for designing protein and peptides of any modality to bind a wide range of biomolecular targets
Introducing Tahoe x-1: a 3-billion-parameter foundation model that learns unified representations of genes, cells, and drugs—achieving state-of-the-art performance across cancer-relevant single-cell biology benchmarks
Introducing Novogaia and Gaia-01: decoding nature’s molecules via development of a foundation model for molecular structure prediction from mass spectrometry data that achieves a 13% performance improvement over the current state of the art
Introducing Valthos: a next-generation biodefense company backed by OpenAI Startup Fund, Lux Capital, and Founders Fund
What we liked on socials channels


Events

Field Trip
Did we miss anything? Would you like to contribute to Decoding Bio by writing a guest post? Drop us a note here or chat with us on Twitter: @decodingbio.