



BioByte 125: decoding the regulome, merge-sort microfluidics, Ibex predictively models antibody conformational states, and targeting improvements for DNA-LNPs




Welcome to Decoding Bio’s BioByte: each week our writing collective highlight notable news—from the latest scientific papers to the latest funding rounds—and everything in between. All in one place.


What we read
Papers
Native, Spatiotemporal Profiling of the Global Human Regulome [Pino at al., bioRxiv, June 2025]
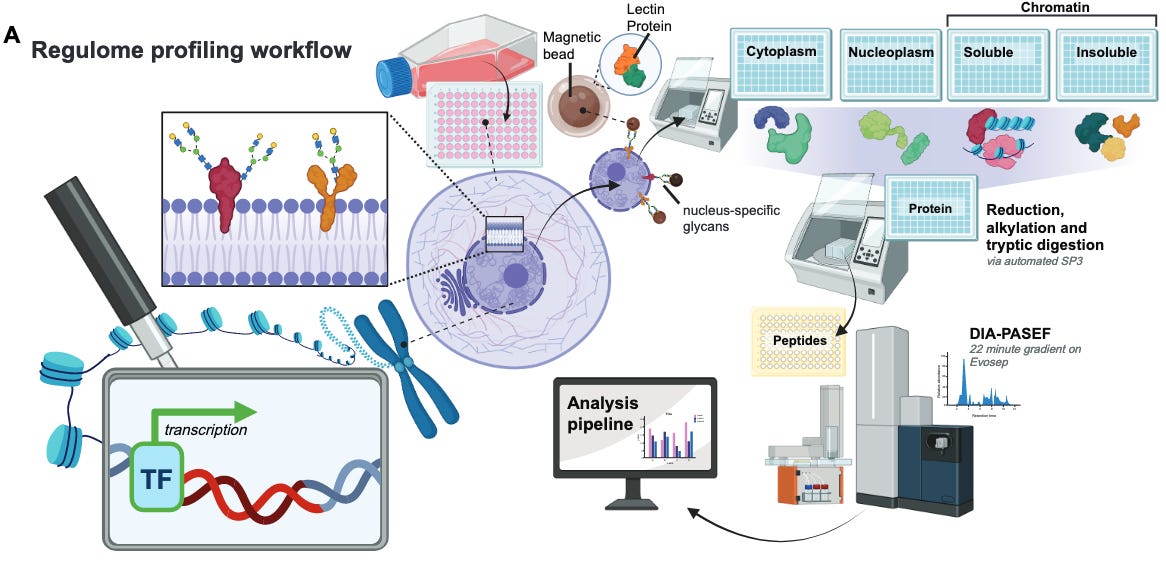
The team at Talus Bioscience has published the Regulome Atlas, a foundational resource for decoding the regulatory proteome, or regulome. The regulome is defined as “the complex ensemble of proteins that integrate cellular signaling pathways and then bind DNA and chromatin to dynamically orchestrate transcriptional programs”, which include transcription factors, cofactors, chromatin remodelers, histone-modifying enzymes, RNA-binding regulators and architectural proteins. These proteins are critical in development, homeostasis and disease but are difficult to measure at scale due to low abundance, transient binding and extensive post-translational regulation.
Genomics-based assays such as ATAC-Seq, DNase-seq and motif analysis have been able to provide a view into protein localization on the genome; ChIP-seq has also provided profiling of individual proteins. Yet, a scalable atlas that quantifies the proteins that make up the regulome has been out of reach.
The Regulome Atlas details the abundance and nuclear localization of regulatory proteins across 36 human cell lines in major tissue types and cancer lineages. It also tracks regulome dynamics in response to stimuli and perturbations. To build this atlas, the team coupled chromatin fractionation with high-throughput, label-free DIA mass spectrometry. This approach resolves identification and quantification of DNA- and chromatin-associated proteins without genetic tagging or crosslinking.
Conformation-Aware Structure Prediction of Antigen-Recognizing Immune Proteins [Dreyer et al., arXiv, July 2025]
While methods like AlphaFold have revolutionized protein structure prediction, current deep learning models still struggle to recapitulate the conformational variability of biomolecules. Achieving greater performance on tasks like modeling protein-protein interactions requires that new tools can accurately model the conformational landscape of proteins and complexes. While some approaches have leveraged vast databases of molecular dynamics (MD) data and simulated protein trajectories, such methods are limited by the inherently short timescales of MD and the challenges of sampling rarer conformational states. However, therapeutic design efforts tend to prioritize strong predictions for bound and unbound protein states, lending weight to recent research efforts that probe single structure prediction models like AlphaFold to generate distinct conformational structures rather than a whole ensemble.
This week, a team from Prescient Design has released the Ibex model, capable of modeling the apo/holo (unbound/bound) conformational states of antibodies, nanobodies, and T-cell receptors. Ibex is heavily based on the original AlphaFold2 (AF2) model architecture. Since the complementarity determining regions (CDRs) of antibodies do not face the same evolutionary conservation constraints as larger protein structures, the use of AF2 does not carry the computational cost of multiple sequence alignment. To allow their adapted model to generate two structure predictions per antibody CDR, the authors introduce a conformation token that designates a training structure as apo or holo. This token’s information is passed on from the input embedding to each module in AF2’s structure block, and can be specified at the time of inference to produce a corresponding antibody structure.
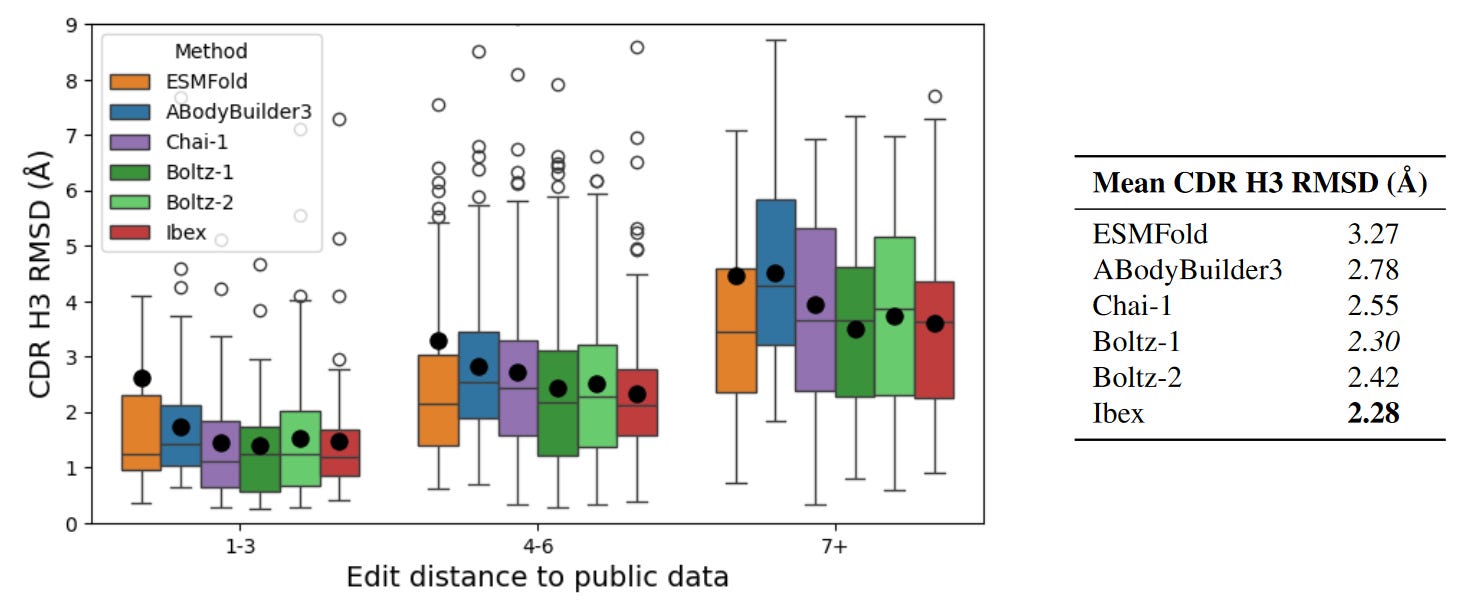
The authors showcased Ibex’s performance on CDR-H3 related tasks, specifically since the domain is a key determinant of antibody binding specificity. First measuring the root mean square deviation (RSMD) between predicted and ground truth structures as a baseline measure of structural accuracy, the team showed that Ibex could reasonably capture the conformational variability of bound and unbound states; however, the model did struggle with high RMSD examples. Ibex was also compared to models that could only output a single structural prediction for a given antibody sequence. As expected, single predicted structures failed to account for the RMSD between different states compared to pairs of predictions from Ibex. Ibex was also compared with contemporary structure prediction tools like ESMFold, Boltz-1, and Chai-1, as well as more bespoke models for antibodies, nanobodies, and TCRs. All models achieved relatively similar performance on benchmarks, with Ibex particularly excelling on CDR alpha and beta-3 TCR loops. The most interesting performance evaluation was on a private dataset of antibody structures which was built to ensure a minimum edit distance from publicly available datasets. Here, Ibex demonstrated the lowest mean RMSD on CDR-H3 loops across a range of edit distances, proving the model’s competitive performance on out of distribution data.
While by no means a dramatic improvement in structure prediction performance, Ibex demonstrates the potential to use preexisting models like AF2 and adapt them with innovations like conformation tokens. The authors note that similar tokens can be added to indicate other information about allostery and environmental conditions like pH. Finally, while Ibex cannot currently capture multiple states revealed by experimental data, it will be interesting to see how Prescient Design and Genentech potentially integrate the model with their lab-in-the-loop approach to address its current challenges.
Targeting DNA-LNPs to Endothelial Cells Improves Expression Magnitude, Duration, and Specificity [Marzolini et al., bioRxiv, July 2025]
COVID-19 led to a boon in mRNA-LNP technology, which proved to be quick to design, scalable to manufacture, and safe for gene expression without causing immunogenicity. Despite these benefits, this approach lags behind viral-based gene delivery mechanisms in long-term gene expression, the size of the payload possible, and the ability to deliver complex DNA designs. In 2024, researchers from Jacob Brenner’s lab at UPenn unveiled technology to deliver plasmid DNA to cells using LNPs. In this follow up work, they upgrade their LNP delivery vehicle with antibody fragments targeting endothelial cells, reducing off-target delivery to the liver and increasing long-term expression to at least 14 days.
Before diving into the paper, let’s touch on the role of immunogenicity in gene therapies. When foreign DNA or RNA are detected in cells, they activate the innate immune system, which tries to eliminate the foreign genetic payload (this protects us from bacteria and viruses). This reduces the half-life of the gene therapy, which for many use cases isn’t ideal. In 2005, Katalin Kariko famously circumnavigated this problem for mRNA-based gene therapy by using modified nucleosides (m5C, m6A, m5U, s2U, pseudouridine) to prevent immunogenicity, which enabled mRNA-based therapeutics to flourish. This is also a challenge with delivering plasmid DNA through LNPs. To solve this, Brenner’s lab added nitro-oleic acid to their LNP formulations - this lipid inhibits the STING pathway responsible for recognizing and destroying foreign DNA. DNA holds at least three main advantages over RNA for gene therapies. First, there are more complex switches that you can apply with DNA than in RNA such as regulatory elements like inducible promoters. Second, plasmid DNA is significantly cheaper to manufacture than mRNA. Third, DNA innately has a longer half-life than mRNA, enabling more durable expression of your gene therapy of interest. The current paper extends this last advantage, by targeting gene delivery specifically to endothelial cells with long half-lives.
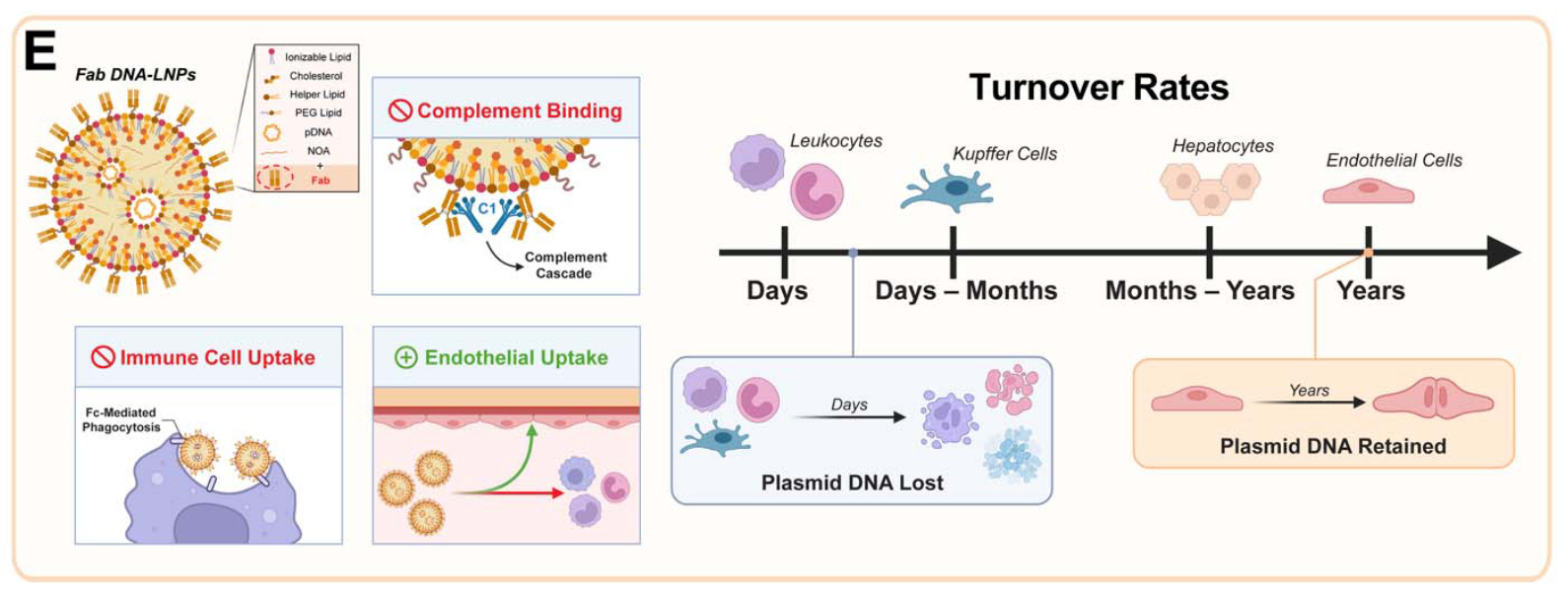
To achieve organ-specific delivery, the researchers conjugated antibodies to the surface of their DNA-LNPs. Attaching antibodies against PECAM-1, a protein on the surface of endothelial cells, redirected nanoparticle delivery to the lungs with remarkable efficiency (~90% of the injected dose per gram of tissue). To demonstrate the platform's versatility, they also showed that using an antibody against VCAM-1 could effectively target the spleen and brain. Critically, switching from a full monoclonal antibody (mAb) to a smaller antibody fragment (Fab) for lung targeting dramatically improved outcomes. While initial delivery to the lungs was similar, the Fab-LNP expression at 14 days was nearly ten times higher than with mAbs and showed superior specificity. The lung-to-liver expression ratio for Fab-LNPs soared from 27:1 at day 1 to 111:1 by day 14. The authors attribute this to the fact that expression in the liver is in short-lived cells, while the targeted lung endothelial cells are quiescent and provide stable, long-term expression.
In the original 2024 paper, Brenner’s lab demonstrated transgene expression lasting up to 6 months (compare that to ~1day for mRNA). The authors only share data for up to 14 days after DNA-LNP delivery, at which there is still durable expression, indicating the true durability of this gene therapy may be significantly longer.
Deterministic Cell Pairing with Simultaneous Microfluidic Merging and Sorting of Droplets [Joslin et al., bioRxiv, July 2025]
At the intersection of chip fabrication, fluid dynamics, and bioanalytical chemistry, microfluidics introduces control over volumes typically not controllable by hand. First invented in the form of an etched silicon wafer in 1979 in Silicon Valley [1], the notion of controlling liquids with high precision is not new. From pipettes to single-cell sequencing to generation of entire drug discovery libraries, the applications microfluidics have unlocked in the field of bioengineering are vastly impactful.
In this preprint Joslin M. et al. proposed merge-sort: a droplet microfluidics-based tool capable of creating entire libraries of cell pairs to study cell-cell interactions from. Unlike previous studies, merge-sort has a fidelity of pairing and sorting cells with 1:1 ratio droplet encapsulation that makes downstream applications such as profiling the immune response, studying cytotoxicity, and finding treatments to kill tumours possible.
So how does it work? Two elements make merge-sort possible. First, a laser is used to detect droplet fluorescence, which, upon laser detection, activates a saltwater electrode with high frequency pulse. Application of this electric field merges droplets in a process known as electrocoalescence. Once merged and charged, droplets can be sorted using a non-uniform electric field. Sorting cells further increased resultant product purity. Figure 1a below demonstrates how an electric pulse allows droplet merging; if no pulse is applied no droplets are merged.
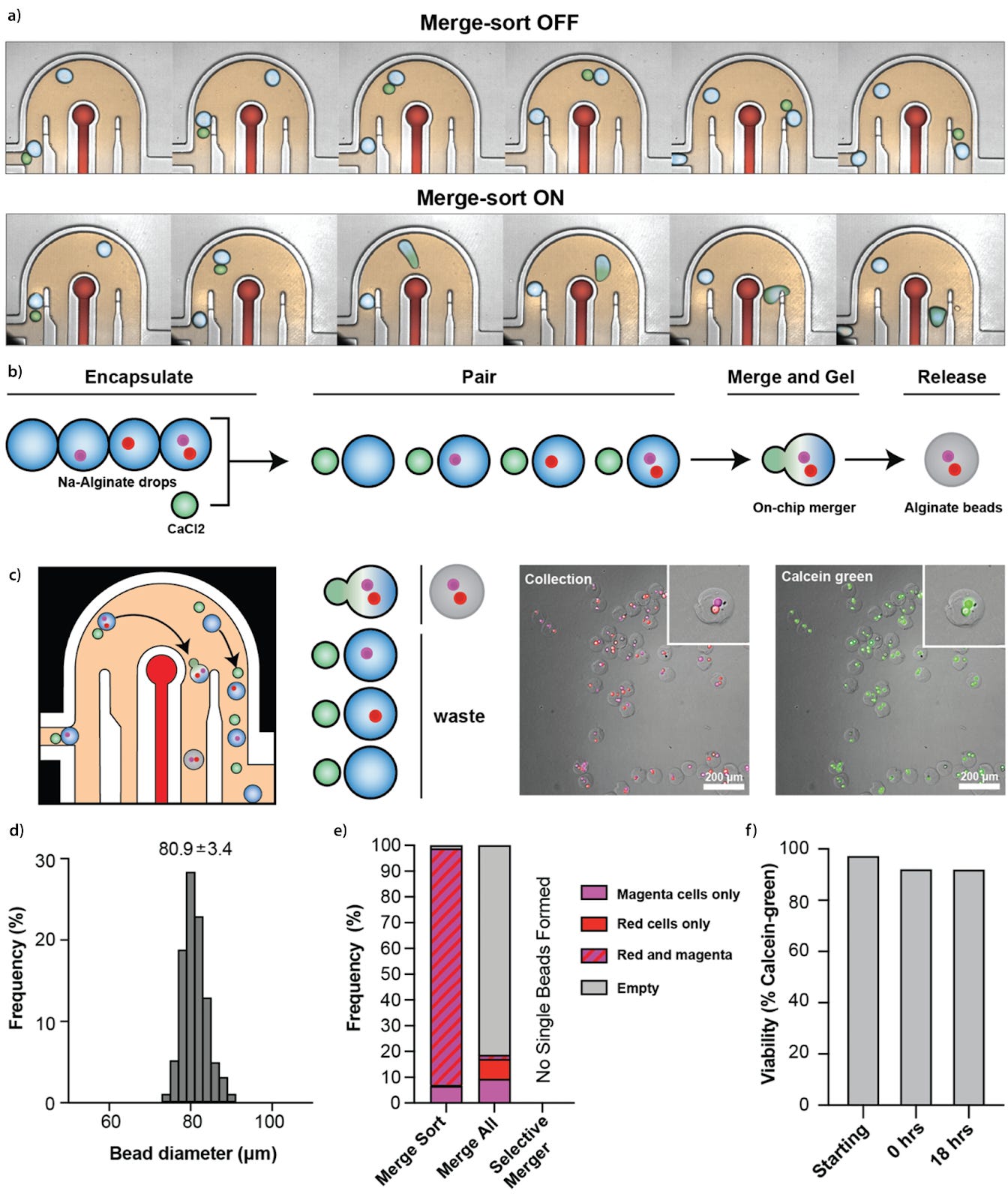
As well as the first proof-of-concept droplet merge-sort shown in figure a), Joslin M. et al. took the technology further and applied it to merging different cell types at 1:1 ratio. As shown in figure b-f) there was precise control over the exact number of cells at 1:1 ratio - achieving 90% accuracy for green:red, and 94% for green:magenta fluorescently labeled cell-cell pairs. Combining the dual-encapsulating alginate beads containing cells with a small calcium bead allowed on-chip hydrogel bead creation. In doing so, encapsulated cell-cell pairs became manipulable, making transfer of cell-cell pairs into new media possible. Achieving cell viability of 92% even after 18 hours of encapsulation (figure f) further makes for a promising time window for developmental and co-culture models.
So what does the encapsulation of cell-cell pairs at high fidelity make uniquely possible? The i) isolated creation of libraries of thousands of cell-cell pair interactions, and ii) ability to expose pairs to further downstream assays in a targeted manner. Just imagine the speed at which entire populations of engineered T-cells expressing chimeric antigen receptors (CARs) could be screened against a tumour, being able to rapidly identify and intervene to fight off tumour cells. Furthermore, because the microfluidic setup operates in an off-chip droplet manner (unlike micro valve-controlled chambers or well-based assays) there is no upper limit to the number of candidate cell-cell pairs being screened, meaning the amount of data that can be collected is resource constraint, not platform constraint.
If one has a platform that can generate new data insights at high-throughput, and perform screens that others are not able to do, a synergistic relationship emerges between data uniqueness, quality, and impact. Whilst engineering of fluid flows and cell encapsulation may appear highly niche, the creation of high-quality engineered tools that interface with the data scales and speeds at which bits are generated will accelerate research in exciting new directions.
La-Proteina: Atomistic Protein Generation via Partially Latent Flow Matching [Geffner et al., arXiv, July 2025]
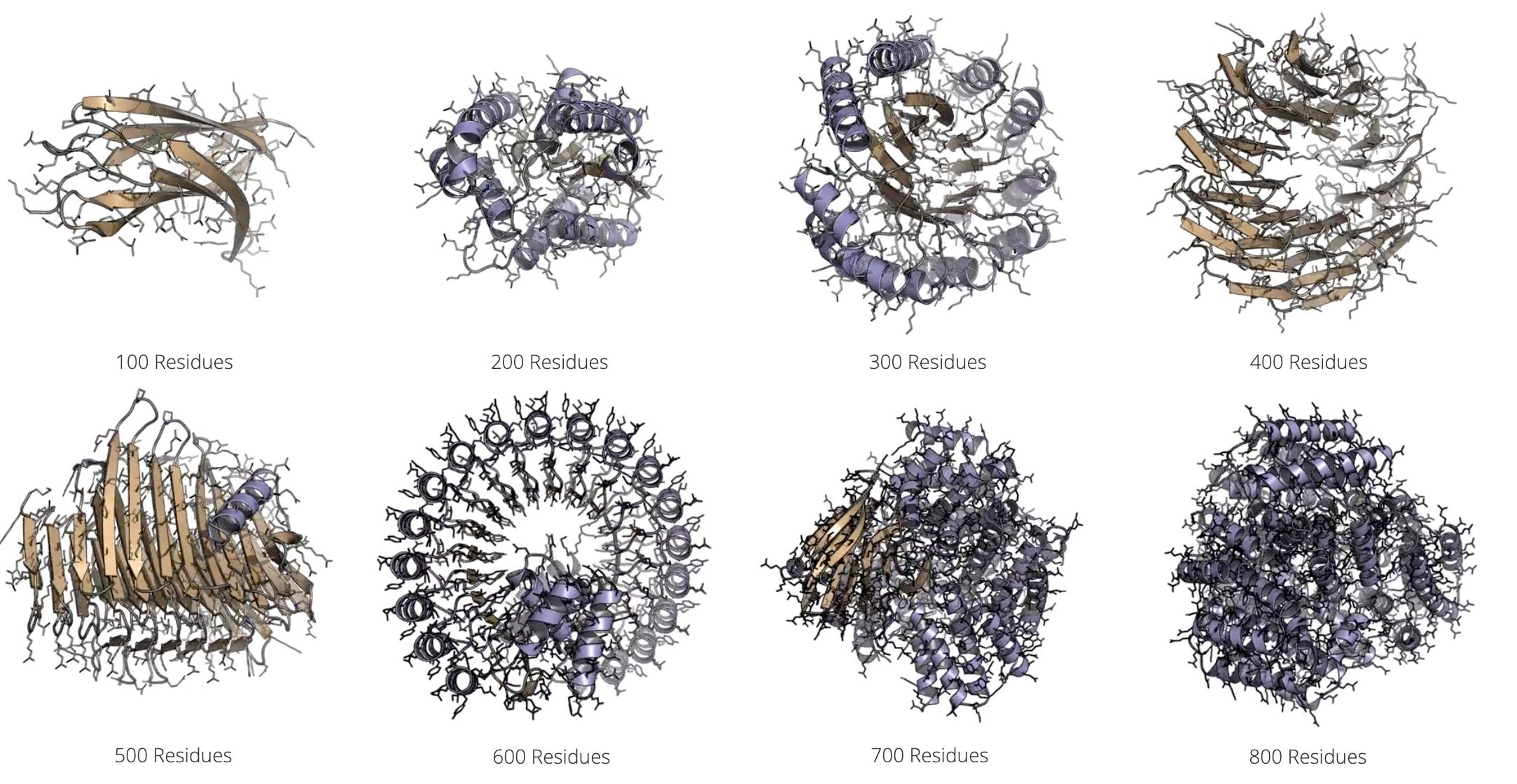
A team from NVIDIA has released La-Proteina, a new de novo protein design tool that uses both explicit and latent modeling to codesign sequence and structure. Specifically, the model specifies alpha carbon coordinates while using a variational autoencoder to model variable length side chain properties in a latent space. La-Proteina showed state of the art performance on all-atom motif scaffolding and tip-atom scaffolding tasks, as well as superior codesignability and diversity of generated proteins up to 800 residues in length.
Notable deals
For their Series C, Varda Space Industries raised $187M in a round led by Natural Capital and Shrug Capital. Khosla Ventures, Lux Capital, Also Capital, Peter Thiel, Founders Fund, and Caffeinated Capital participated as well. Now with its fourth mission currently in orbit, Varda seeks to leverage microgravity to create novel pharmaceutical formulations otherwise impossible on Earth.
23andMe assets are acquired by TTAM Research Institute, a nonprofit founded and led by Anne Wojcicki. Through this acquisition, 23andMe will continue its services of providing customers with personalized DNA testing and insights. The official press release relays an emphasis on customer choice and transparency, with eligibility to opt-out of research participation, as Wojcicki stresses a commitment to operating for “the public good.” Regeneron had previously announced an acquisition bid of $256M in May in hopes of utilizing 23andMe’s substantial data to advance their drug development efforts.
Renasant Bio launched this week with $54.5M in seed funding from 5AM Ventures, Atlas Venture, OrbiMed and Qiming Venture Partners USA. The resources will be used to advance development for their oral corrector, which seeks to remediate misfolding in PC1 and PC2 and halt the progression of autosomal dominant polycystic kidney disease (ADPKD), the leading genetic cause of end-stage renal failure.
Hong Kong-based Sino Biopharmaceutical agreed to purchase LaNova Medicines for $951M. Sino had previously purchased a 4.9% stake in the company in November, and is now acquiring the remaining 95.1%, marking another major move for China’s significant biotech growth. The acquisition is hot on the heels of Merck’s licensing of LaNova’s PD-1xVEGF bispecific antibody for $588M upfront with another $2.7B in potential milestones this past November. AstraZeneca also licensed an ADC from LaNova in 2023 for $55M upfront with another $545M in milestones.

What we liked on socials channels


Field Trip
Did we miss anything? Would you like to contribute to Decoding Bio by writing a guest post? Drop us a note here or chat with us on Twitter: @decodingbio.
 |
|